Container APM 서비스의 HA(High Availability) 테스트
[kt cloud 서비스개발팀 강상구 님]
Container APM 서비스의 HA(High Availability) 테스트
안녕하세요,
kt cloud의 K2P 서비스에 Container APM이라는 모니터링 서비스 옵션이 있다는 사실을 알고 계셨나요? 이번에, 데이터를 수집하는 체계를 단일화하고, 3개의 Master Pod를 통한 고가용성(HA) 구조로 Container APM 서비스가 더욱 고도화되었습니다.
데이터를 모니터링하고 수집된 데이터를 보관하는 APM 서비스에서 VM이나 서비스에 문제가 생겼을 때 데이터의 안정성과 고가용성에 대한 확인이 필요했습니다.
이 글에서는 고도화 과정에서 진행된 HA(High Availability) 기능 테스트의 기록을 간단하게 공유하고자 합니다.
테스트 환경
- kt cloud 포털 스테이징 환경에서 K2P 클러스터 + APM 옵션 상품 생성
- OpenSearch 클러스터는 3대 노드로 구성, 각각의 노드는 Master/Data 노드 역할 수행
- OpenTelemetry를 통한 Metrics/Logs/Traces 데이터 정상 수집 상태
테스트 준비
시험에 앞서 Opensearch Cluster의 상태를 살펴보겠습니다.
이 테스트에서는 kubectl -n opensearch를 ko로 줄여서 작성했습니다.

- K2P APM 서비스를 구성하는 Pods 상태 확인
- opensearch-cluster-master
- data-prepper
- opensearch-dashboard
- opentelemetry-node-collector
- opentelemetry-cluster-collector
Container APM의 구조는 기본적으로 OpenSearch Master Node 3개, OpenSearch Dashboard Pod 1개로 구성됩니다. 그리고 여기에 데이터를 수집하는 OpenTelemetry Pod들과 Data Prepper Pod 3개가 추가로 필요합니다.
오늘 테스트에서는 OpenSearch-cluster-master Pod를 살펴볼 예정입니다.
OpenSearch Dashboard GUI에 접속하여, 대시보드에서 제공하는 Dev Tools를 사용해 OpenSearch 클러스터의 상태를 확인해봅시다.
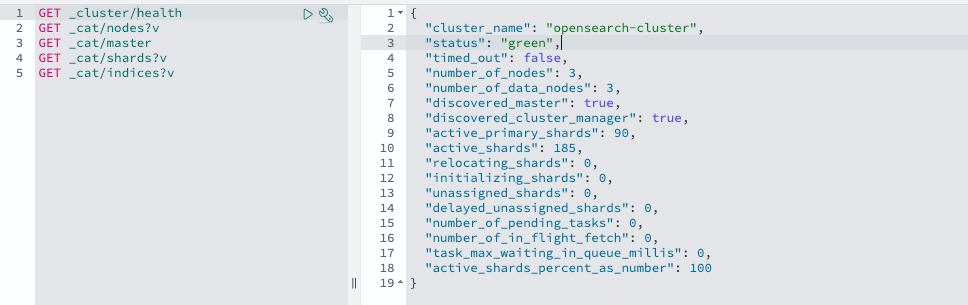
해당 API 리턴 값을 통해 우리는 여러 가지 정보를 알 수 있습니다.
- status: “green” ← 모든 프라이머리 및 복제 샤드가 할당되어, 클러스터 정상 상태
- number_of_nodes: 3 ← 클러스터에 총 3개의 노드가 존재
- active_primary_shards: 90 ← 90개의 활성 프라이머리 샤드
- unassigned_shards: 0 ← 할당되지 않은 샤드 없음
그렇다면 프라이머리 샤드(primary shards)와 레플리카 샤드(replica shards)는 무엇일까요? OpenSearch가 데이터를 다루는 방식을 이해하는 것이 중요합니다.
클러스터가 green 상태일 때는, 모든 primary와 replica 샤드가 노드에 정상적으로 할당된 상태입니다. OpenSearch에서는 기본적으로 프라이머리 샤드 1개와 레플리카 샤드 1개를 생성하며, 이 샤드들이 3개의 노드에 분산 저장됩니다. 이를 통해 데이터는 안전하게 분산 저장되고, 고가용성을 유지할 수 있습니다.
- 참고: 클러스터 상태 구분
- green - 모든 primary 샤드와 replica가 노드에 할당 (모든 데이터가 안전하게 저장되고 복제된 상태)
- yellow - 모든 primary 샤드는 노드에 할당 되었지만 일부 replica는 할당되지 않음 (일부 장애 상황에서 데이터 손실의 위험이 있음)
- red - 최소 하나의 primary 샤드가 노드에 할당되지 않음 (데이터 접근이 불가하고, 데이터 손실이나 클러스터 기능 중단의 위험)
- OpenSearch 클러스터 노드 상태 확인

-
- 3개 마스터 노드 확인 가능
- opensearch-cluster-master-2 번 pod가 리더 역할 수행
- 인덱스 상태 확인

- 모든 인덱스 health 는 green 상태 확인 (primary, replica 샤드 모두 정상 할당)
- 인덱스별 샤드 저장 상태 확인

-
- index 데이터는 primary 1, replica 1 샤드 할당되어 STARED 상태 (정상적으로 read, write 가능)
그럼 이제 샤드가 할당된 노드들에 장애를 발생시켜 보겠습니다. 이를 통해 데이터가 안전하게 저장되는지, 그리고 OpenSearch의 기능이 정상적으로 작동하는지 확인할 수 있을 것 같습니다.
테스트 시나리오
- OpenSerach Master 노드 1대 중단 후 복원
- OpenSerach Master 노드 2대(과반수 이상) 중단 후 복원
Test 1 - OpenSearch Master 노드 1대 중단 후 복원
1.1 Openseach 클러스터 매니저 노드 장애 발생
클러스터 정보를 조회했을 때 opensearch-cluster-master-2 Pod가 클러스터 매니저 노드인 것을 확인했습니다.
이 Pod는 hsg-apm-stage.option11 노드에 위치하고 있습니다. (kubectl get pod -o wide 명령어로 확인)
이제 해당 VM을 정지시켜 보겠습니다.

1.2 Opensearch 클러스터 상태 확인 (green → yellow)
Opensearch 클러스터의 상태가 어떻게 변하는지 살펴볼까요.
- pods 상태

- opensearch-cluster-master-0 pod 중단 상태
- Opensearch Pod는 각 노드당 하나씩 생성되도록 설정 → 재생성되지 않음
Dashboard의 Dev tool을 이용해 더 자세히 살펴보겠습니다.
- OpenSearch 클러스터 상태 확인

- status: yellow ← 클러스터는 작동 가능하지만, 일부 복제본이 없기 때문에 데이터 복구 능력이 떨어질 수 있음
- number_of_nodes: 2 ← 1개 노드 장애 발생으로 전체 노드수는 2개
- unassigned_shards: 44 ← 장애가 발생한 노드에 저장된 데이터, 아직 새로운 노드에 할당되지 않은 샤드 개수
- OpenSearch 클러스터 노드 상태 확인

- opensearch-cluster-master-1 노드가 클러스터 리더로 새롭게 선출
OpenSearch 클러스터에서 Manager Node가 사라지면, 남아 있는 노드들 중에서 새로운 Manager Node가 자동으로 선출되는 것을 확인할 수 있습니다
- 인덱스 상태 확인

- 중단된 노드에 저장된 샤드의 복제본을 새로운 노드에 할당하는 동안, 해당 인덱스는 yellow 상태로 표시됩니다.
- 샤드 상태 확인

-
- 중단된 노드에 저장된 샤드를 새로운 노드에 복제본으로 할당 중인 인덱스는 UNASSIGNED 상태로 표시
- 복제본을 이용해 데이터를 새롭게 할당중인 인덱스는 INITIALIZING 상태로 표시
정지된 Pod에 할당됐던 데이터가 다른 노드로 이동하면서 INITIALIZING 상태의 인덱스가 보입니다. 이 작업이 모두 완료되고 Opensearch Node에 primary shards와 replica shards가 Opensearch Node에 할당되면 모두 STARTED 상태로 변한다는 것을 예측할 수 있습니다.
이 작업이 끝나도록 잠시 기다린 뒤 다시 클러스터 상태를 조회하겠습니다.
1.3 Opensearch 클러스터 상태 확인 (yellow → green)
- OpenSearch 클러스터 상태 확인
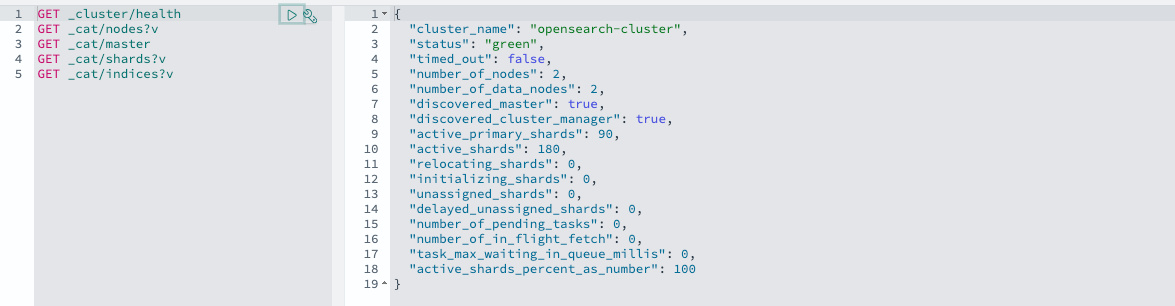
-
- status : green ← 모든 프라이머리 및 복제 샤드가 할당되어 있고 클러스터가 정상 상태임을 의미
- unassigned_shards : 0 ← 할당되지 않은 샤드는 없음
Unassigned 상태의 샤드가 모두 사라지고 클러스터의 상태가 Yellow에서 Green으로 돌아온 것을 확인할 수 있었습니다.
- 인덱스 상태 확인

-
- 모든 인덱스 health 는 green로 정상 상태 확인
- 샤드 상태 확인

- 모든 데이터 index 는 primary 1개, replica 1개 샤드로 각각 노드에 분산 저장됨, STARTED 상태 확인
- 중단된 노드 opensearch-cluster-master-2 노드를 제외하고 샤드가 할당됨
중단된 노드에 저장된 샤드들이 다른 노드로 이동하여 백업된 것을 확인할 수 있었습니다.
- Dashboard 서비스

-
- 마스터 1개 노드 장애 발생 시, Dashboard 서비스 정상 동작
- 단, dashboard pod가 배포된 노드에 장애 발생 시, 다른 노드로 재배포 되는 동안 dashboard 서비스 접속 장애 발생
- NotReady Node 항목에 1개 노드 중단 상태 확인 가능
- 마스터 1개 노드 장애 발생 시, Dashboard 서비스 정상 동작
모든 복구가 완료됐으니 이제 정지된 VM을 다시 작동해서 Opensearch 클러스터를 정상화하고 변화를 살펴보겠습니다.
1.4 장애 복구 후 클러스터 상태 확인 (Opensearch 노드 3개 정상화)
- VM 재가동 → opensearch-cluster-master-2 pod 재시작
- pod 상태 확인

- OpenSearch 클러스터 상태 확인

- status : green
- number_of_nodes: 3 ← 모든 노드 정상 동작 확인
- OpenSearch 클러스터 노드 상태 확인

- opensearch-cluster-master-2 클러스터 추가 확인
- 인덱스 상태 확인

- 인덱스별 샤드 저장 상태 확인
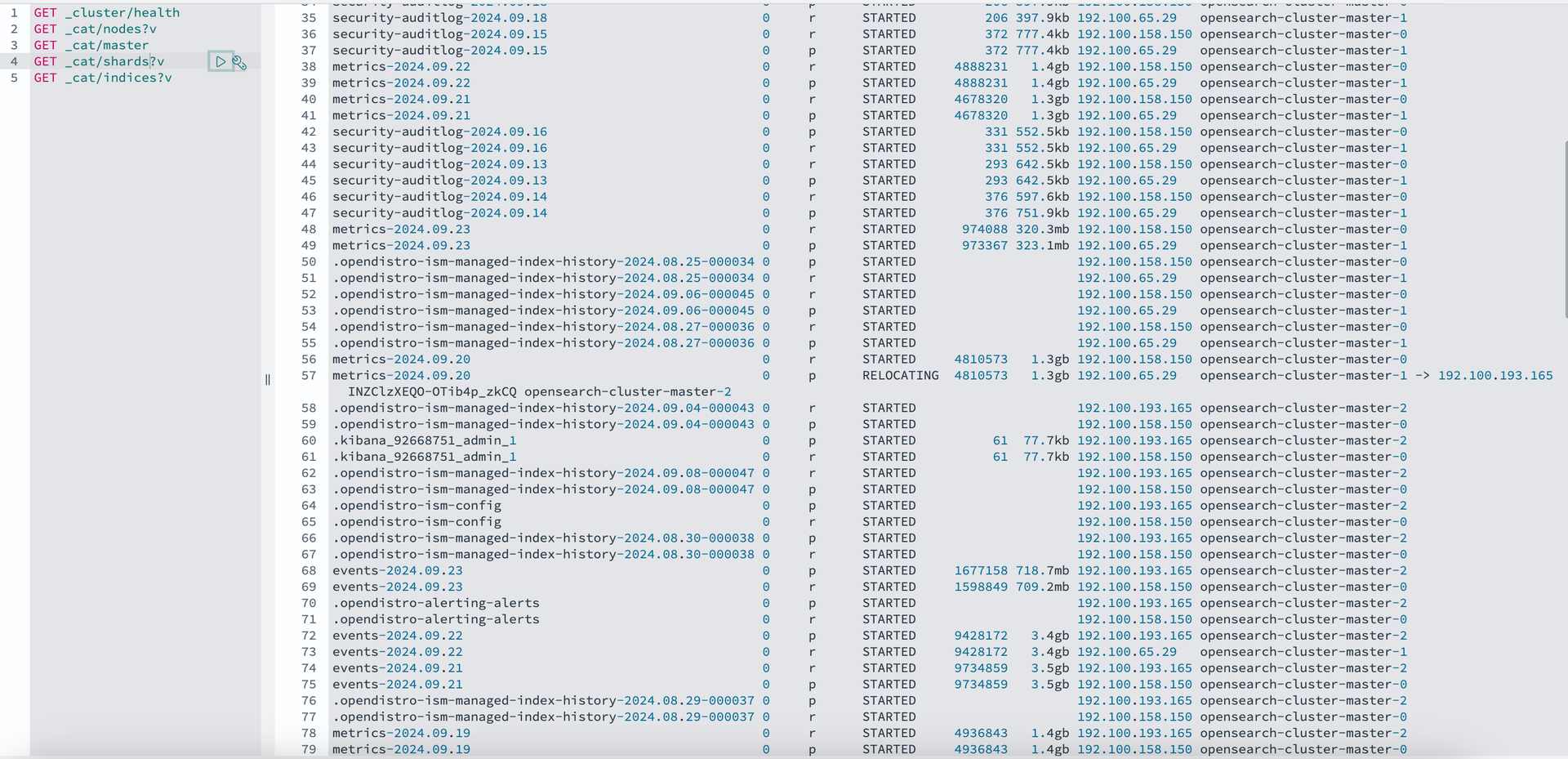
-
- opensearch-cluster-master-2 클러스터에 샤드 저장 확인
- 일부 인덱스는 opensearch-cluster-master-2 로 Relocating 진행
인덱스별 샤드의 저장 위치를 살펴보니 2번 노드가 정지된 상태에서 0과1번 노드로 이동했던 일부 샤드들이 2번이 연결되자 다시 2번으로 이동하는 Relocating 작업이 진행중입니다.
노드 간의 리밸런싱(균형 조정) 과정에서 Opensearch는 샤드를 최적화된 상태로 재배치하여 성능을 극대화하고 노드의 자원 균형 상태를 확인한다는 것을 알 수 있습니다.
- dashboard 서비스 확인

-
- NotReady Node 는 0 으로 변경 확인, 클러스터 이상 무
TEST 1 결과
Opensearch 클러스터를 구성하는 노드 하나가 장애를 일으키더라도 데이터는 안전하게 보존되며 Opensearch의 자체 리밸런싱을 통해 클러스터의 성능을 최적화 한다는 것을 확인할 수 있었습니다.
Test 2 - OpenSerach Master 노드 2대(과반수 이상) 중단 후 복원
이번엔 클러스터를 구성하는 3대의 Opensearch 노드중 2대가 중단됐을땐 어떤 현상이 일어나나 확인해보겠습니다.
테스트 1번과 동일하게 매니저 노드가 있는 VM을 정지한 후 새롭게 선출된 매니저 노드도 VM을 정지해 멈춰보겠습니다.
2.1 - 매니저(리더) 클러스터 VM 정지
- 첫번째 매니저 노드 확인 후 VM 정지

- 2번째 매니저 노드 확인 후 VM 정지

 2개의 VM이 정지된 상태
2개의 VM이 정지된 상태
VM 2개가 정지된 상태에서 Opensearch Pod의 상태를 살펴봅니다

그럼 이제 1개의 노드만 남았을 때, OpenSearch의 상태를 살펴보겠습니다
2.2 - OpenSearch 클러스터 상태 확인
- OpenSearch 클러스터 노드 상태 확인 - 504 Time-out

Dashboard dev tool을 이용해 API 요청을 날려보니 Time-out 응답이 날아왔습니다. Opensearch 클러스터가 정상 상태가 아닌 것을 알 수 있습니다.
- 인덱스 수집 상태 확인

- 인덱스 수집/저장 중단 상태 확인
인덱스 수집/저장도 노드가 멈춘 이후에는 정지된 것을 볼 수 있습니다.
- Data-Prepper pod 로그 확인

- Data-Prepper와 OpenSearch 클러스터 간 pipeline 구성 실패 로그 확인 가능
더 자세히 알아보기 위해, 데이터를 변환해 OpenSearch로 전송하는 Data-Prepper의 로그를 확인해 보니, 파이프라인 구성이 실패했다는 로그가 나타났습니다.
3개의 클러스터 구성 노드 중 1개만 남았을 때, OpenSearch의 기능이 중단되는 것을 확인할 수 있었습니다. 그렇다면 저장된 데이터는 안전하게 보존될 수 있을까요?
중단된 노드를 다시 정상화하여 데이터가 그대로 남아있는지 확인해 보겠습니다.
3.3 - OpenSearch 클러스터 노드 1개 정상화
먼저 하나의 VM을 다시 동작시키고 정보를 조회해보겠습니다.
- pods 상태 확인

이제 2개의 Opensearch Pod가 Running 상태입니다.
Dev tool을 이용해 API로 클러스터 상태를 체크해보겠습니다.
- 클러스터 상태 확인

- 클러스터 상태 - RED
OpenSearch API는 정상적으로 응답하지만 아직 클러스터 상태는 Red입니다.
아마도 일부 Primary 샤드의 미할당이 원인으로 보입니다.
- OpenSearch 클러스터 상태 확인

- opensearch-cluster-master-0 번 노드가 리더로 선출
이제 2개의 노드가 있기때문에 1개의 노드가 리더로 선출된 것을 볼 수 있습니다.
- 인덱스 상태 확인

- 다수 샤드 상태가 yellow로 확인 (replica 샤드 미할당)
첫번째 테스트에서 봤었던 replica 샤드 미할당으로 인한 yellow state의 샤드가 많이 보입니다.
- 샤드 상태 확인

- replica 샤드 할당이 필요한 샤드는 UNASSIGNED 상태
첫 번째 테스트와 마찬가지로, 아직 할당이 필요한 샤드들은 UNASSIGNED 상태로 나타나며, 새롭게 할당 중인 샤드들은 INITIALIZING 상태로 표시됩니다.
- Dashboards 상태 확인
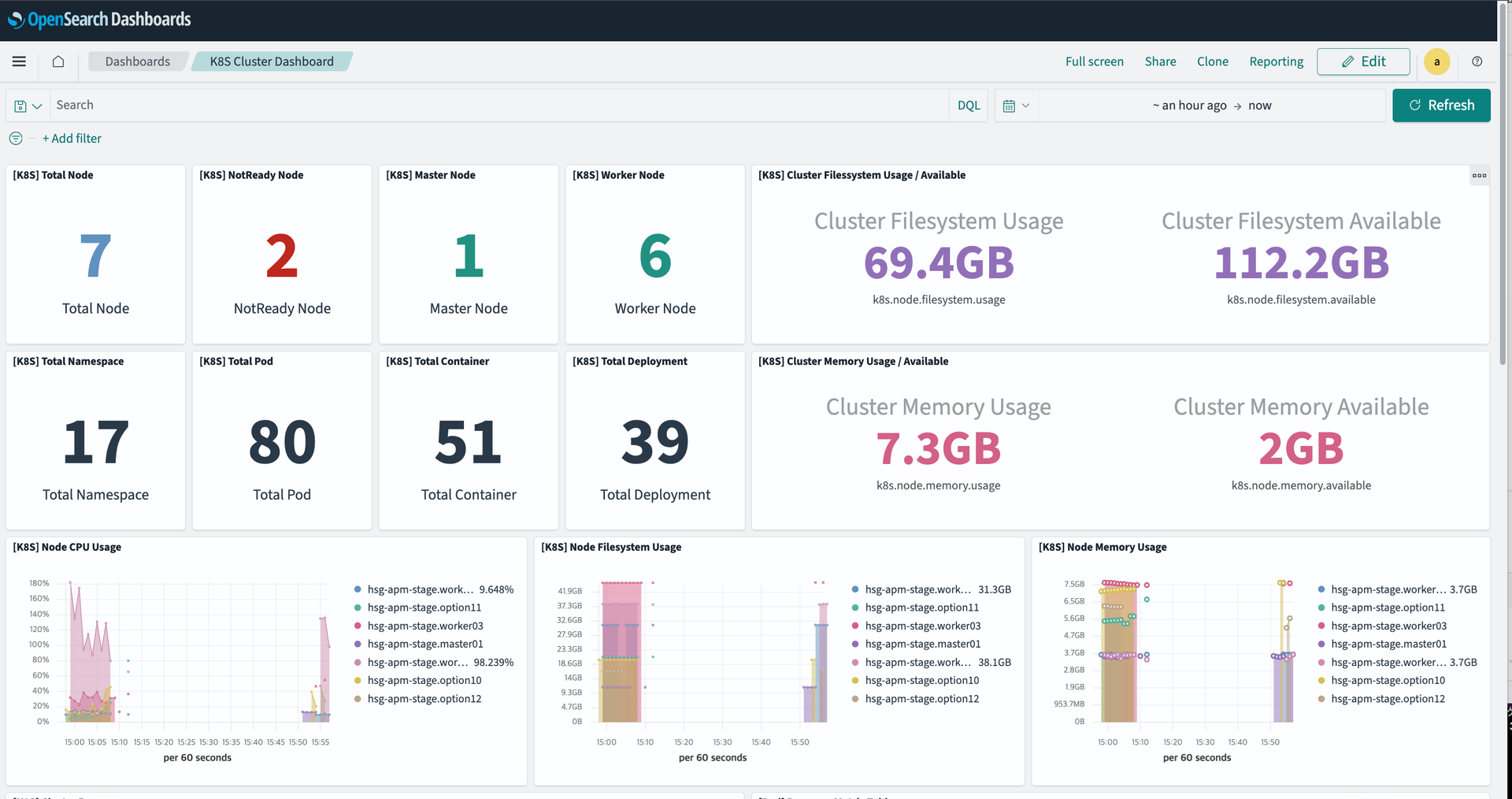
- 일정 시점 데이터 수집 안된 상태 및 현재 정상 수집 상태 확인 가능
데이터의 수집이 다시 정상적인 것을 가운데가 비어있는 그래프의 모양을 통해 확인할 수 있었습니다.
하지만 NotReady Node수는 아직 업데이트 되지 않았네요. 이후 1개로 업데이트 됐습니다.
- OpenSearch 클러스터 상태 확인

- unassigned_shards : 50 (replica 샤드 할당 필요)
아직 50개의 샤드가 할당이 필요한 것을 클러스터 상태로 볼 수 있었습니다. 잠시 시간을 기다렸다 API를 다시 호출해보겠습니다.
- 일정 시간 후 OpenSearch 클러스터 상태 확인

- unassigned_shards : 43 (replica 샤드 할당 필요)
동작이 멈췃다가 다시 진행이 되고 있어서인지 샤드 할당에 걸리는 시간이 아직 더 필요해보입니다. 하지만 하나씩 진행되고 있는 것을 확인할 수 있었습니다.
3.4 - OpenSearch 클러스터 전체 노드 정상화
이제 클러스터 전체 3개의 노드를 모두 정상화시켜보겠습니다.
- 3개 pod Running 상태 확인

- 클러스터 노드 상태 확인

- OpenSearch 클러스터 상태 확인

- yellow 상태에서 replica 샤드 할당 완료 후 green 으로 변경
시간이 흘러 replica 샤드의 할당이 완료되어 클러스터 상태도 Green으로 변경된 것을 확인할 수 있습니다.
- 인덱스 상태 확인

- 모든 인덱스 상태가 green (read, write 가능)
- 인덱스별 샤드 저장 상태 확인
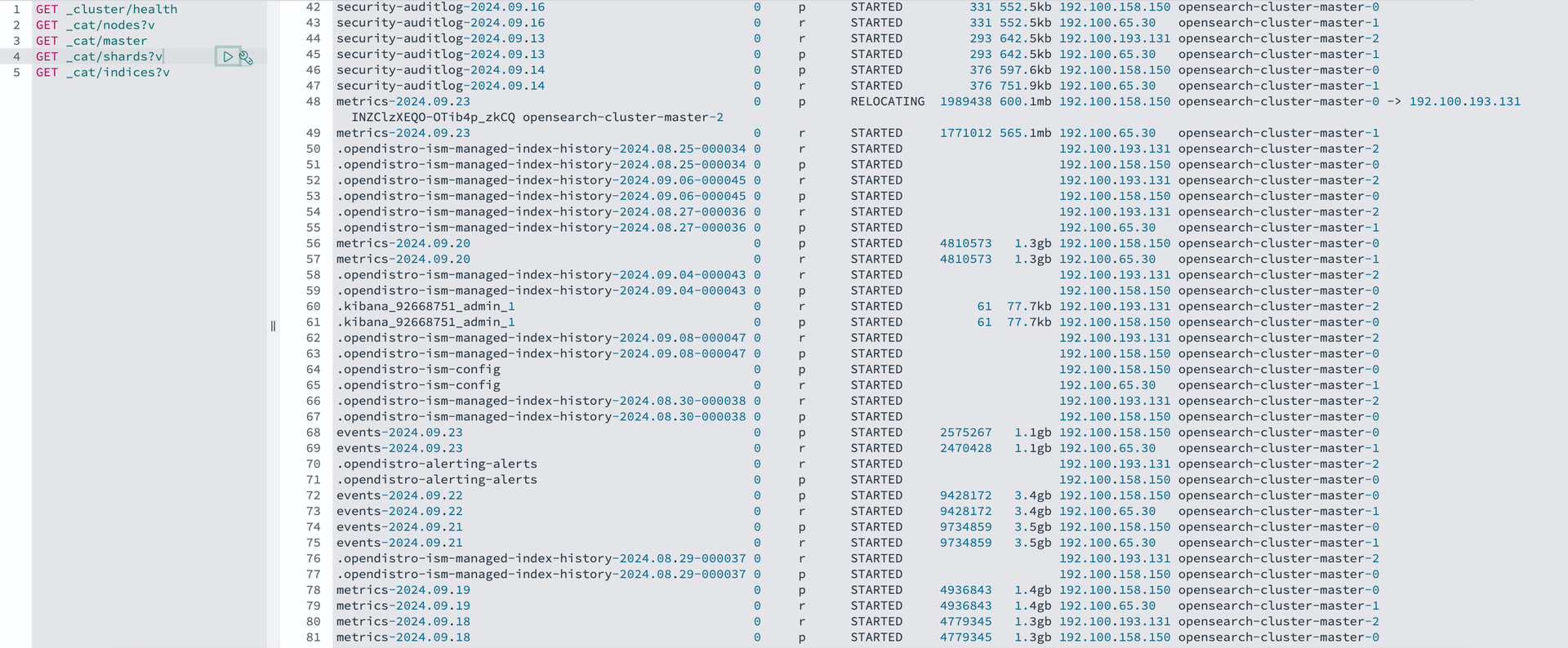
- 모든 인덱스 복원 후 relocating 프로세스 진행
- OpenSearch Dashboard 서비스 확인
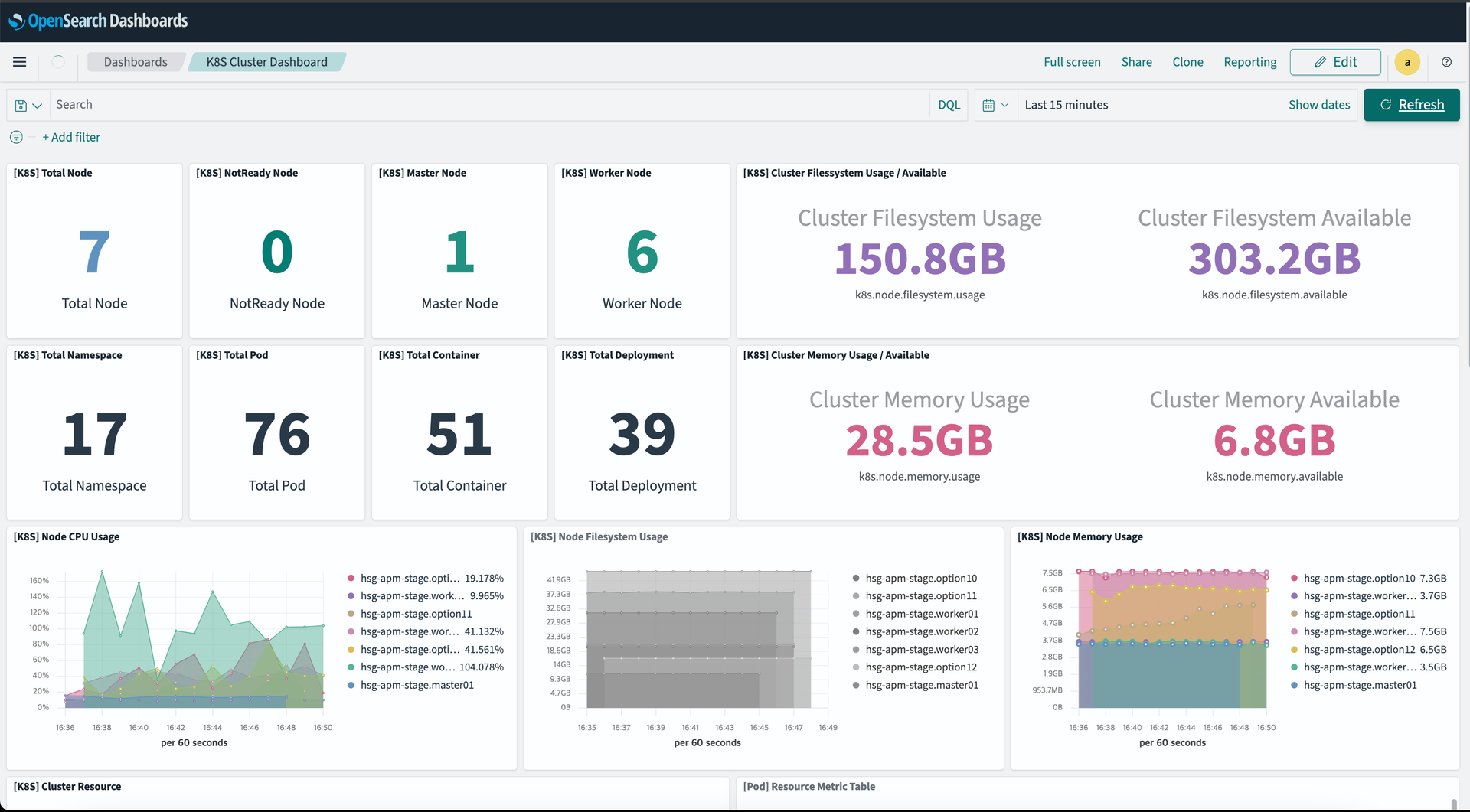
- 최근 15분 데이터 정상 상태 확인 가능
TEST 2 결과
이 테스트를 통해 특정 Node나 Opensearch Master Pod에 문제가 생기더라도 데이터는 안전하게 복구될 수 있다는 사실을 확인할 수 있었습니다.
테스트 결과
2개 이상의 노드로 구성되어 있을때 OpenSearch가 정상적으로 데이터를 수집하고, 모니터링이 가능하다는 것과 OpenSearch 클러스터의 기능이 잠시 멈추더라도 데이터 보관의 안정성 및 클러스터의 복구 기능을 확인할 수 있었습니다.
VM과 POD의 모니터링 기능과 수집 데이터의 안정성이 확보된 Container APM 서비스, 한번 이용해보세요!