NPU로 sLM 서빙하기: 새로운 가능성 탐구
[kt cloud AI플랫폼팀 최지우 님]
NPU로 sLM 서빙하기: 새로운 가능성 탐구
AI 기술이 발전함에 따라, AI 모델의 효율적인 배포와 운영을 위한 새로운 처리 장치도 개발되고 있습니다. 이 과정에서 NPU(Neural Processing Unit)라는 새로운 주자가 등장했습니다. NPU는 인공 신경망 연산을 위해 특별히 설계된 프로세서로, 기존의 GPU(Graphics Processing Unit)와는 다른 방식으로 AI 워크로드를 처리합니다.
NPU는 대규모 병렬 처리를 가능하게 하며, 특히 신경망 연산에 최적화되어 있습니다. 이로 인해 NPU는 적은 전력으로 높은 성능을 낼 수 있습니다. AI 모델의 학습과 추론 과정에서 NPU는 더욱 효율적인 데이터 흐름과 메모리 관리로 성능을 크게 향상시킵니다.
NPU의 구조와 기능
NPU는 기본적으로 행렬 연산과 벡터 연산을 처리하는 데 최적화된 구조를 가지고 있습니다. AI 연산에서 가장 많이 사용되는 계산 방식인 행렬 곱셈과 같은 수학적 연산을 빠르게 수행할 수 있도록 다양한 처리 유닛을 병렬로 배치하여 대량의 데이터를 동시에 처리합니다. 이러한 병렬 처리 능력은 NPU가 높은 성능을 발휘하는 주된 이유 중 하나입니다.
NPU는 여러 가지 신경망 아키텍처를 지원하며, 특히 딥러닝 모델의 경우 더 효과적으로 처리할 수 있습니다. 딥러닝은 여러 층(layer)으로 구성된 신경망 구조를 사용하여 데이터의 패턴을 학습하고 예측하는 방식으로, NPU는 이러한 복잡한 구조의 연산을 가속화하는 데 적합합니다.
최근에는 AI 서비스의 수요가 증가함에 따라, 데이터 센터의 운영 비용이 증가하는 문제가 발생하고 있습니다. NPU는 성능을 유지하면서도 전력 소모를 줄여 전체 운영 비용을 절감할 수 있는 솔루션을 제공합니다. NPU는 전력 소모를 최소화하면서 높은 성능을 발휘합니다. 이는 AI 연산이 복잡하고 계산량이 많음에도 불구하고, 배터리로 작동하는 모바일 기기나 IoT 장치에서도 널리 사용될 수 있도록 합니다. 당장 삼성 갤럭시 스마트폰과 애플 아이폰에서도 NPU를 탑재하여 이미지 인식, 음성 인식 등의 AI 기능을 효율적으로 처리하고 있습니다.
GPU? NPU?? TPU???
GPU는 수천 개의 코어를 통해 대규모 병렬 연산을 처리할 수 있어 이미지, 동영상, 게임 같은 그래픽 처리에 유리합니다. 그 강력한 병렬 처리 능력 덕분에 AI 연산에도 널리 사용되고 있습니다. 그러나 GPU는 범용 프로세서와 비슷한 구조를 유지하여 다양한 데이터 유형과 연산 방식을 지원하지만, 그만큼 전력 소비가 높고 특정 AI 연산에 비해 효율이 떨어지는 경우도 있습니다.
GPU 시장은 NVIDIA, AMD, Intel 등 여러 기업이 참여하고 있지만, NVIDIA가 사실상 독점적인 위치를 차지하고 있습니다. 그로 인해 많은 개발자와 기업들이 NVIDIA의 GPU 하드웨어와 CUDA 소프트웨어 생태계에 의존하고 있습니다.
NPU는 그래픽 처리를 지원하지 않지만, 인공 신경망 연산에 특화된 하드웨어 가속기로서 AI 모델의 효율적인 실행을 위해 설계되었습니다. 넓은 의미에서 보면 Google의 TPU, AWS의 Inferentia와 Trainium, 그리고 Intel의 Gaudi 등 모두 NPU라고 볼 수 있습니다. 인공 신경망 연산에 특화된 하드웨어 가속기라는 점에서 공통점을 가지고 있기 때문입니다. 그러나 각 NPU 제조사는 자신들의 특화된 아키텍처를 강조하기 위해 다른 이름을 사용합니다.
- Google TPU(Tensor Processing Unit): Tensor 연산에 최적화되어 있으며, AI 프레임워크인 TensorFlow와의 통합이 강점입니다.
- AWS Inferentia / Trainium: 각각 추론과 훈련에 최적화되어 있으며, AWS 생태계 내에서 AI 모델 제공을 위한 비용 효율성과 성능을 극대화하는 데 중점을 두고 있습니다.
- Intel Gaudi: 대규모 모델 훈련을 위해 설계되어 있으며, INT8과 FP16 같은 저정밀 연산을 지원해 속도와 효율성을 높였습니다.
kt cloud의 NPU 서비스
kt cloud는 리벨리온 사의 NPU인 ATOM 칩을 클라우드 플랫폼으로 제공하며, 최신 AI 워크로드에 최적화된 컴퓨팅 성능을 지원하고 있습니다. ATOM NPU는 전통적인 GPU 대비 저전력과 고성능의 장점을 갖춰, 특히 추론 작업에서 효율을 극대화합니다. 국내 양산 모델 중 유일하게 트랜스포머 기반 소규모 언어 모델(sLM)을 비롯해 다양한 생성형 AI 모델 가속을 지원합니다. 이를 통해 사용자는 AI 모델을 보다 빠르게 추론하고, 비용 절감 효과를 누릴 수 있으며, 클라우드 환경에서 높은 수준의 유연성과 확장성을 경험할 수 있습니다.

AI SERV에서 NPU로 HuggingFace 모델 서빙하기
이제 kt cloud에서 제공하는 AI SERV NPU 환경에서 실제로 모델(Llama3-8B)을 서빙하는 과정을 보여드리겠습니다.
1. 모델 폴더, 자동 마운트 폴더 생성
먼저 AI SERV - Data & Model 탭에 진입하여 폴더 두 개를 생성합니다.
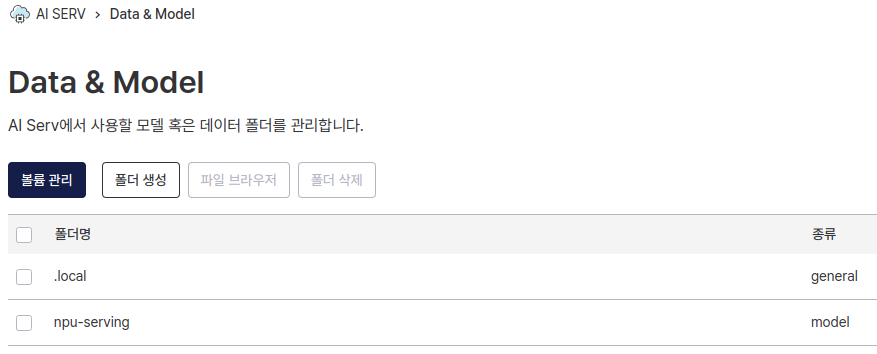
- npu-serving : ‘Model’ 타입의 폴더로, 모델을 저장하고 실행시킬 코드를 저장하는 주 작업 공간입니다.
- .local : ‘General’ 타입의 폴더로, 파이썬 패키지들을 pip으로 설치하면 해당 폴더에 저장됩니다. 폴더명이 '.'으로 시작하는 폴더들은 컨테이너 생성 시 자동으로 마운트됩니다.
2. NPU 칩이 할당된 컨테이너 생성하기
그 다음 Container 탭에 진입하여 NPU가 할당된 컨테이너를 생성합니다. 자원 그룹을 ‘ATOM Plus’로 선택하고, 1번 단계에서 만든 폴더를 선택하여 마운트합니다. Llama3-8B 모델을 탑재하기 위해 4장의 NPU 칩 사양을 선택해야 합니다.
- 16 Core 128 GB 4 Atom+
- atom-tensorflow-pytorch 3.10

3. 개발환경 실행 및 기본 패키지 설치
컨테이너 생성이 완료되면, 개발 환경 접속을 위해 ‘앱 실행’ 버튼을 눌러 원하는 개발 환경에 접속합니다. 환경에 접속하면 기본 디렉토리는 /home/work 로 설정되어 있으며, 이전 단계에 마운트한 폴더들은 work 디렉토리 하위에 연결되어 있습니다.

접속하여 터미널에 rbln-stat을 입력하면, 할당되어 있는 NPU 칩의 상태를 확인할 수 있습니다.

먼저 NPU(ATOM)를 사용하기 위한 필수 SDK를 설치합니다.
| pip install -i https://pypi.rbln.ai/simple rebel-compiler # 컴파일러 설치 pip install -i https://pypi.rbln.ai/simple optimum-rbln # Huggingface Transformer 모델 연동 라이브러리 |
여기서 설치한 패키지들은 자동으로 마운트되는 .local 폴더에 저장되기 때문에, 컨테이너를 삭제하고 재생성하여도 유지됩니다.
4. HuggingFace 모델 ATOM Compile 하기
먼저 HuggingFace에서 모델을 로드하여 ATOM에서 동작할 수 있도록 컴파일하는 과정을 거쳐야 합니다. 컴파일을 위한 코드는 아래와 같습니다.
| # compile.py from optimum.rbln import RBLNLlamaForCausalLM model_id = "meta-llama/Meta-Llama-3-8B-Instruct" compiled_model = RBLNLlamaForCausalLM.from_pretrained( model_id=model_id, export=True, rbln_batch_size=1, rbln_max_seq_len=8192, rbln_tensor_parallel_size=4, # 4개의 NPU 칩 대상으로 컴파일 ) compiled_model.save_pretrained("llama3") |
모델에 따라 HuggingFace의 모델 접근 권한이 필요합니다. Llama3의 경우 모델 페이지에서 접근 권한 신청을 먼저 진행해야합니다.
이 과정이 완료되면 작업 디렉토리 하위에 ‘llama3’ 디렉토리가 신규로 생성되며, 그 안에 컴파일된 모델 데이터가 저장됩니다.
5. NPU를 통해 모델 추론하기
이제 NPU에 모델을 탑재하고 추론 코드를 돌려볼 수 있습니다. 아래와 같은 코드를 통해 문장을 생성해봅니다.
| from transformers import LlamaTokenizer, AutoTokenizer from optimum.rbln import RBLNLlamaForCausalLM # 컴파일된 모델 로드 compiled_model = RBLNLlamaForCausalLM.from_pretrained( model_id="./llama3", export=False, ) # Tokenizer 준비 tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", padding_side="left") tokenizer.pad_token = tokenizer.eos_token # 대화 준비 conversation = [{"role": "user", "content": "안녕. 한국어로 자기소개 해봐"}] text = tokenizer.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False) inputs = tokenizer(text, return_tensors="pt", padding=True) # 문장 생성 generation_kwargs = dict( **inputs, do_sample=False, max_length=4096, ) # 모델로부터 응답 생성 output = compiled_model.generate(**generation_kwargs) # 생성된 토큰을 텍스트로 변환하여 출력 decoded_output = tokenizer.decode(output[0], skip_special_tokens=True).split("assistant")[1].strip() print(decoded_output) |
출력
| 안녕하세요! 저는 LLaMA, AI입니다. 저는 인공지능 언어 모델로, 다양한 언어를 이해하고 응답할 수 있습니다. 저는 한국어를 포함하여 30개 이상의 언어를 지원합니다. 저는 다양한 주제에 대한 정보를 제공하고, 대화하고, 글을 작성할 수 있습니다. 저와 함께 대화를 즐기세요! |
상당히 매끄러운 문장이 생성되는 것을 확인할 수 있습니다. 여기까지 NPU를 사용한 추론 테스트까지 완료하였습니다.
6.모델 서비스 생성
마지막으로, 모델을 서빙하는 단계입니다. AI SERV는 외부에서 추론 API를 호출할 수 있도록, 모델 서비스에 필요한 엔드포인트와 포트를 제공합니다. 모델 서비스를 생성하면, 정의된 모델과 코드를 기반으로 필요한 수의 컨테이너를 자동으로 실행하여 배포합니다. 트래픽이 증가해 컨테이너 스케일링이 필요할 경우, 원하는 컨테이너 수를 조정하기만 하면 자동으로 컨테이너가 복제되고, 로드 밸런싱도 자동으로 처리됩니다.
먼저 API 서버를 동작시키기 위한 스크립트를 구성하여야 합니다. 일반적으로는 추론 API를 호출할 수 있는 API 서버를 연동시키지만, 이번에는 실제로 채팅 UI까지 확인할 수 있도록 Gradio를 이용하여 서버를 실행시키는 스크립트를 작성해보겠습니다. 위에서 실행한 추론코드를 변형합니다.
| # server.py import gradio as gr from transformers import AutoTokenizer from optimum.rbln import RBLNLlamaForCausalLM compiled_model = RBLNLlamaForCausalLM.from_pretrained( model_id="./llama3", export=False, ) tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", padding_side="left") tokenizer.pad_token = tokenizer.eos_token # 채팅 함수 def chat(user_input, chat_history): # 대화 입력 생성 conversation = [{"role": "user", "content": user_input}] text = tokenizer.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False) inputs = tokenizer(text, return_tensors="pt", padding=True) # 문장 생성 generation_kwargs = dict( **inputs, do_sample=False, max_length=4096, ) output = compiled_model.generate(**generation_kwargs) # 모델로부터 응답 생성 decoded_output = tokenizer.decode(output[0], skip_special_tokens=True) # 생성된 토큰을 텍스트로 변환 response = decoded_output.split("assistant")[1].strip() if "assistant" in decoded_output else decoded_output chat_history.append((user_input, response)) # 채팅 기록에 사용자 입력과 모델 응답 추가 return chat_history # Gradio 인터페이스 구성 with gr.Blocks() as demo: chatbot = gr.Chatbot() msg = gr.Textbox(label="Your message") clear = gr.Button("Clear") msg.submit(chat, [msg, chatbot], chatbot) # 메시지를 제출할 때 chat 함수 호출 clear.click(lambda: None, None, chatbot) # Gradio 실행 demo.launch(server_name="0.0.0.0", server_port=7860) |
그 다음 모델 정의 파일(model-definition.yaml)을 작성하여야 합니다. 모델 폴더 하위에 model-definition.yaml을 생성하고 아래와 같이 내용을 채워 넣습니다.
| models: - name: "npu-llama3-chat" # 아무 이름 model_path: "/models" # 모델이 정의된 경로(설정한 모델 폴더는 자동으로 /models로 마운트됩니다) service: # 서비스 정의 start_command: ["python", "server.py"] # 실행 코드 port: 7860 # Gradio 서버 연결 포트 health_check: path: / # Health Check path max_retries: 5 |
model-definition.yaml 파일에 대한 자세한 작성 가이드는 Cloud매뉴얼(https://manual.cloud.kt.com/kt/ai-serv-serving)에서 확인하실 수 있습니다.
이제 다시 Cloud 콘솔로 돌아와 Model Serving 탭에서 모델 서비스를 생성합니다. 모델 서비스 생성은 컨테이너 생성 단계와 거의 동일합니다. 서비스 명을 입력하고, 동일한 자원 그룹(ATOM Plus), 동일한 이미지와 컨테이너 사양을 설정합니다. 마운트할 폴더는 지금까지 작업한 폴더를 선택하면 됩니다.
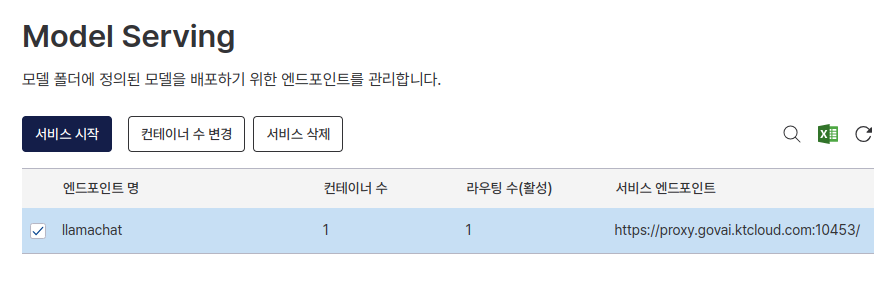
탭으로 돌아와서 조금 기다리면, 컨테이너가 자동 실행되고 서비스 엔드포인트가 생성되어 있습니다. 해당 URL을 복사하여 접속하면 server.py에서 구성한 Gradio 서버가 실행 중인 것을 확인할 수 있습니다.
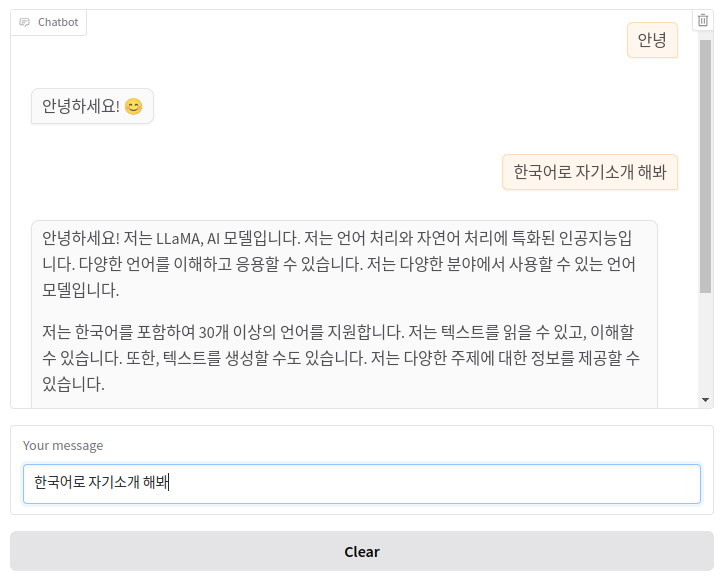
ChatGPT와 같은 서비스가 완성되었습니다. 이처럼 AI SERV에서는 단순히 추론 API 서버 뿐만 아니라, 서비스 자체도 배포하여 테스트해볼 수 있습니다.
NPU의 진가: 선택의 갈림길
급변하는 AI 시장에서는 새로운 워크로드와 모델이 지속적으로 등장하고 있지만, NPU는 이를 신속하게 적용하기 어렵습니다. 따라서 고정된 AI 모델을 사용하는 경우에 적합한 옵션이라 할 수 있습니다. 초기 세팅에 다소 노력을 들인다면, NPU는 GPU에 비해 훨씬 저렴한 가격으로 운영할 수 있습니다.
결국, NPU와 GPU 중 어떤 선택을 할지는 사용자에게 달려 있습니다. NPU의 초기 투자와 세팅을 통해 장기적인 비용 절감을 추구하고, 혁신적인 AI 솔루션을 실현할 것인지, 아니면 손쉬운 운영과 익숙함을 위해 고비용의 GPU를 선택할 것인지 고민해볼 시점입니다.
NPU는 분명 매력적인 선택지입니다. 하지만 새로운 HW 아키텍처와 이를 지원하는 SW 아키텍처의 새로움으로 인해 최적의 결과에 도달하려면 인내와 참을성이 필요할 수 있습니다. 기술의 진정한 가치는 사용자가 어떻게 선택하고 활용하느냐에 달려 있습니다.
기타/참고
리벨리온 SDK 유저 가이드: https://docs.rbln.ai/ko/index.html
kt cloud AI SERV 모델 서빙 가이드: https://manual.cloud.kt.com/kt/ai-serv-serving