OpenStack 컴퓨팅 서비스 이해하기: 심화편
[kt cloud CloudSW운영팀 김호균 님]
OpenStack 컴퓨팅 서비스 이해하기: 심화편
지난 포스팅에서는 컴퓨팅 서비스인 Nova의 아키텍처와 기본 동작 과정에 대해서 간단히 살펴보았습니다. 또한 OpenStack 대시보드 서비스인 Horizon을 통해 가상 머신을 직접 생성해 보고, 이 과정에서 OpenStack의 여러 컴포넌트들이 어떻게 서로 상호 작용하는지 알아보았습니다.
이번 포스팅에서는 가상화 관점에서 Nova를 좀 더 자세히 살펴보겠습니다.
OpenStack 가상화 방식: KVM과 QEMU
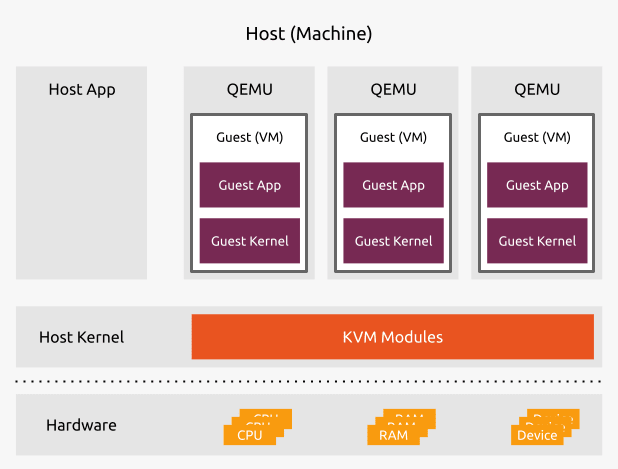
Nova에 대해 설명하기 전에, KVM과 QEMU에 대해 먼저 알아보겠습니다.
가상화 방식을 활용하면 호스트 시스템과 독립적인 환경에서 각각 다른 운영체제로 가상 머신(VM)을 동작할 수 있습니다. 이를테면, 리눅스 위에 윈도우와 리눅스를 동시에 운영할 수 있습니다. OpenStack에서는 다양한 하이퍼바이저를 지원하지만, 일반적으로 사용되는 가상화 방식은 KVM과 QEMU입니다.
KVM(Kernel-based Virtual Machine)은 리눅스 운영체제에 내장된 커널 모듈로, 리눅스 커널과 통합되어 하드웨어의 특수 가상화 기능을 활용할 수 있도록 지원합니다. KVM을 활성화하면 게스트 OS를 특별히 수정하지 않고도 각 가상 머신이 자체 커널을 실행할 수 있으며, 이로 인해 리눅스 커널 자체가 하이퍼바이저처럼 동작하게 됩니다. 덕분에 리눅스 서버는 물리적 하드웨어 자원을 관리함과 동시에 여러 가상 머신을 관리할 수 있는 가상화 플랫폼이 됩니다.
QEMU(Quick Emulator)는 하드웨어 가상화를 소프트웨어 레벨에서 에뮬레이션하는 도구입니다. 여기서 에뮬레이션이란, “완전히 다른 종류의 컴퓨터 시스템을 만들어 그 위에서 프로그램을 실행할 수 있게 해주는 것”입니다. 예를 들면 x86 아키텍처의 호스트에서 ARM 기반 시스템을 구현할 수 있습니다. 다시 말해, 소프트웨어 방식으로 다른 아키텍처를 흉내낼 수 있도록 해줍니다.
KVM과 QEMU를 같이 사용하는 이유?

클라우드 서비스에서는 다양한 하드웨어 환경을 가상 머신에서 제공해야 합니다. 예를 들어, CPU, 메모리, 네트워크 장치, 그래픽 카드, 디스크 등 여러 종류의 하드웨어가 필요합니다.
QEMU는 소프트웨어 에뮬레이션을 통해 하드웨어 가상화를 수행하지만, 이 과정에서 CPU 명령어를 소프트웨어로 변환하는 방식으로 인해 속도가 느려지는 단점이 있습니다. 이때 KVM의 가상화(하드웨어 가속) 기능을 사용하면, 가상 머신과 호스트의 아키텍처가 동일한 환경에서 가상 머신이 CPU 명령어를 직접 실행할 수 있어 거의 물리 서버에 가까운 성능을 낼 수 있습니다.
정리하면, KVM은 CPU와 메모리의 고속 가상화를 담당하고, QEMU는 네트워크, 디스크와 같은 I/O 장치의 에뮬레이션을 담당합니다. 따라서 KVM과 QEMU를 함께 사용하면 고성능의 가상 머신 기능(KVM)과 폭넓은 하드웨어 호환성 및 다양한 아키텍처 지원(QEMU)을 동시에 제공할 수 있어, 높은 성능과 다양한 가상화 환경이 요구되는 클라우드 서비스에서 유리하게 활용될 수 있습니다.
OpenStack에서 Nova와 libvirt의 역할
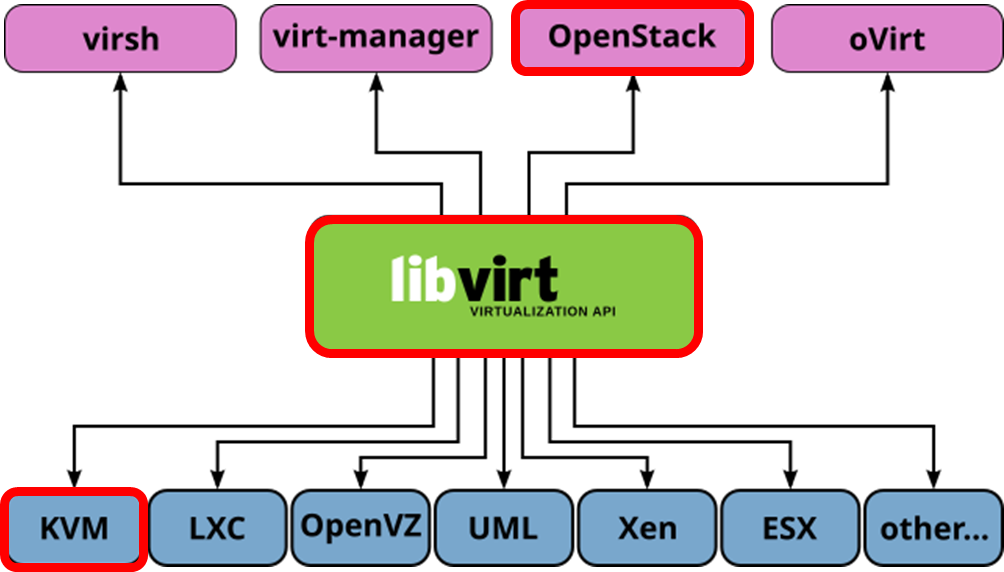
KVM과 QEMU가 실제 가상 머신을 실행하고 성능을 향상시키는 역할을 한다는 것을 앞서 살펴보았습니다. libvirt는 이러한 가상화 환경을 관리하고 제어하는 라이브러리로, 사용자가 KVM-QEMU 스택을 쉽게 제어할 수 있도록 인터페이스 역할을 합니다. OpenStack의 Nova도 마찬가지로 libvirt를 통하여 KVM-QEMU에 접근합니다.
그렇다면 Nova의 역할은 무엇일까요? Nova 자체는 가상화를 수행하지 않습니다. Nova는 API의 집합이며, 가상 머신 생성 요청을 받으면, libvirt 드라이버를 통해 하이퍼바이저(KVM-QEMU)에 명령을 전달합니다. 즉, OpenStack의 컴퓨팅 가상화 스택에서 Nova는 고수준의 관리를 담당하고, libvirt는 하이퍼바이저와 직접 상호작용하는 저수준 제어를 담당합니다.
OpenStack과 Nova를 추가로 사용하는 장점?

OpenStack의 컴퓨팅 가상화 스택은 고수준 인터페이스인 Nova와 저수준의 관리와 제어를 담당하는 libvirt, 그리고 실제 가상화를 담당하는 KVM-QEMU로 구성된다는 것까지 알아보았습니다.
그렇다면 왜 KVM-QEMU만 사용하지 않고, 추가로 OpenStack과 Nova를 사용하는 것일까요?
OpenStack은 스택(Stack)이라는 단위로 클라우드 서비스 인프라를 구성합니다. 여기에는 가상 머신, 네트워크, 스토리지, 보안 설정 등의 인프라 리소스들이 포함됩니다. Stack에 정의된 리소스들은 여러 호스트에 걸쳐 배치되고 서로 연결되어 하나의 통합된 클라우드 환경을 제공합니다.
따라서 고수준의 인터페이스인 Nova를 사용하면 가상 머신에 대한 라이프사이클 관리뿐 만 아니라, 스케줄링, 네트워킹, 스토리지 등 클라우드 환경의 다양한 기능을 연동함으로써 호스트를 넘나드는 제어와 관리가 가능해지게 되는 것입니다.
코드로 nova-compute 동작 이해하기
지금까지 OpenStack의 컴퓨팅 가상화 스택 전반에 대해 심도 있게 훑어보았습니다. Nova 아키텍처에서 실제 가상화 작업을 수행하는 핵심 구성 요소는 nova-compute입니다. nova-compute는 nova-scheduler가 선택한 호스트에서 가상 머신을 생성하며, Neutron, Cinder 등과 협력하여 네트워크와 스토리지를 설정합니다.
이제 nova-compute가 저수준 인터페이스인 libvirt와 어떻게 상호작용하는지 코드를 통해 직접 확인해 보겠습니다.
nova-compute의 주요 로직 코드는 nova/compute/manager.py 에서 확인할 수 있습니다.
| # nova/compute/manager.py def build_and_run_instance(self, context, instance, image, request_spec, filter_properties, accel_uuids, admin_password=None, injected_files=None, requested_networks=None, security_groups=None, block_device_mapping=None, node=None, limits=None, host_list=None): # 가상 머신을 생성하고 실행하는 주요 메서드 self._build_and_run_instance(...) |
해당 메서드를 자세히 확인해 보겠습니다.
| def _build_and_run_instance(self, context, instance, image, injected_files, admin_password, requested_networks, security_groups, block_device_mapping, node, limits, filter_properties, request_spec=None, accel_uuids=None): # (1) 네트워크, 스토리지 등 자원 준비 단계 with self._build_resources(context, instance, requested_networks, security_groups, image_meta, block_device_mapping, provider_mapping, accel_uuids) as resources: # 상태 설정 및 변경사항 저장 instance.vm_state = vm_states.BUILDING instance.task_state = task_states.SPAWNING instance.save(expected_task_state=task_states.BLOCK_DEVICE_MAPPING) # 리소스 정보 준비 block_device_info = resources['block_device_info'] network_info = resources['network_info'] accel_info = resources['accel_info'] # (2) 인스턴스 생성 (하이퍼바이저 드라이버에 전달) self.driver.spawn(...) |
_build_resources() 메서드는 인스턴스 생성 과정에서 상태를 설정하고 변경 사항을 저장합니다. 이 메서드는 인스턴스에 필요한 디스크와 네트워크 정보를 수집하여 자원을 준비한 후, libvirt 드라이버의 driver.spawn() 메서드를 호출해 인스턴스를 실제로 생성합니다.
libvirt 드라이버는 nova/virt/libvirt/driver.py 파일에 구현되어 있습니다.
| # nova/virt/libvirt/driver.py import libvirt class LibvirtDriver(driver.ComputeDriver): def spawn(self, context, instance, image_meta, injected_files, admin_password, allocations, network_info=None, block_device_info=None, power_on=True, accel_info=None): ... # 도메인 XML 생성 xml = self._get_guest_xml(context, instance, network_info, disk_info, image_meta, block_device_info=block_device_info, mdevs=mdevs, accel_info=accel_info) # 게스트 생성 및 네트워크 설정 self._create_guest_with_network(...) LOG.debug("Guest created on hypervisor", instance=instance) |
libvirt와 상호작용하기 위해 XML 구성 파일을 기반으로 가상 머신을 생성하는 코드가 담겨 있습니다. 이 과정에서 VM을 생성하기 위해서는 필요한 설정 정보가 XML 파일에 정의되며, libvirt는 이 XML 파일을 사용하여 가상 머신을 생성합니다.
먼저 _get_guest_xml() 메서드를 호출해 인스턴스를 정의하는 XML 파일을 생성하고, 이후 _create_guest_with_network() 메서드에서 생성된 XML을 사용해 게스트(가상 머신)를 생성합니다.
libvirt와 통신을 하여 인스턴스를 생성하는 _create_guest_with_network() 코드 내부를 살펴보겠습니다.
| # nova/virt/libvirt/driver.py def _create_guest_with_network(context, xml, instance, network_info, block_device_info, ... ) -> libvirt_guest.Guest: try: with self.virtapi.wait_for_instance_event(...): guest = self._create_guest(...) def _create_guest(self, context, xml, instance, ...) -> libvirt_guest.Guest: try: # XML 기반으로 libvirt 게스트 생성 guest = libvirt_guest.Guest.create(xml, self._host) |
_create_guest() 메서드를 통해 VM의 설정 정보(네트워크, 디스크, CPU)를 정의하여 최종적으로 인스턴스를 생성합니다.
마무리
nova-compute를 통해 인스턴스를 생성 요청을 처리하는 과정을 정리하면 다음과 같습니다.
- Horizon 대시보드 또는 CLI를 통해 인스턴스 생성 요청
- nova-api는 이 요청을 받아 nova-compute에 전달
- nova-compute는 build_and_run_instance() 에서 가상 머신 생성 로직 시작
- driver.spawn() 메서드를 호출하여 libvirt 드라이버와 상호작용
- libvirt API를 사용하여 _create_guest() 메서드가 호출되고, 실제 하이퍼바이저에서 인스턴스 생성
위 소스코드는 요약된 버전으로, 핵심 메서드 외에 상당 부분이 생략되어 있습니다.
전체 소스코드는 아래에서 확인할 수 있습니다.
| nova/nova/compute/manager.py at master · openstack/nova · GitHub |
| nova/nova/virt/libvirt/driver.py at master · openstack/nova · GitHub |
참고/출처