

[kt cloud AI플랫폼팀 최지우 님]
GPU 1,000장 모니터링하기: NVIDIA DCGM 활용 전략
AI 플랫폼을 운영하며 수천 장의 GPU를 다루는 일은 결코 단순하지 않습니다. 서버 수가 늘어날수록 관리와 모니터링의 복잡도도 기하급수적으로 증가하고, 그만큼 예상치 못한 문제가 발생할 가능성도 커집니다. 특히 AI 플랫폼을 통해 수많은 고객에게 안정적인 서비스를 제공하려면 GPU 서버의 상태와 성능을 지속적으로 모니터링하는 것이 필수적입니다. 그러나 서버 수가 수백 대에 이르면, 각 GPU의 상태를 일일이 확인하는 것은 사실상 불가능에 가깝습니다.
kt cloud에서는 AI Train, AI SERV 등 GPU 서버를 제공하는 서비스들에서 수천 장의 GPU를 제공하고 있습니다. 저희는 AI 플랫폼팀으로서 이러한 방대한 GPU 자원을 관리하고, 문제를 사전에 예측하여 빠르게 대처하기 위해 효과적인 모니터링 시스템을 구축할 필요가 있었습니다.
이번 글에서는 저희가 GPU 서버들과 각 GPU 디바이스를 모니터링하는 방법과, 이를 통해 장애 인지를 어떻게 실행하고 있는지 구체적으로 설명드리겠습니다.
NVIDIA DCGM(DataCenter GPU Manager)
NVIDIA Data Center GPU Manager(DCGM)는 대규모 GPU 서버 환경을 위한 오픈소스 관리 도구로, NVIDIA가 데이터 센터 내 GPU 상태와 성능을 효율적으로 모니터링하고 관리할 수 있도록 설계한 소프트웨어입니다. DCGM은 각 GPU의 상태와 성능 지표를 실시간으로 파악해 문제를 조기에 발견하고 해결할 수 있도록 돕는 역할을 합니다.
DCGM을 사용하는 주 목적은 GPU 상태 모니터링입니다. GPU의 온도, 전력 소모, 메모리 사용량, 연산 부하와 같은 주요 상태 지표를 실시간으로 수집하여, 각 GPU가 안정적인 상태를 유지하고 있는지 지속적으로 확인할 수 있습니다. 이로 인해 장애 발생 전에 문제를 예측하고 예방하는 데 효과적입니다. 물론 장애가 발생한 후에도 어떤 디바이스에서 문제가 발생하였는지 식별할 수 있는 지표도 제공됩니다.
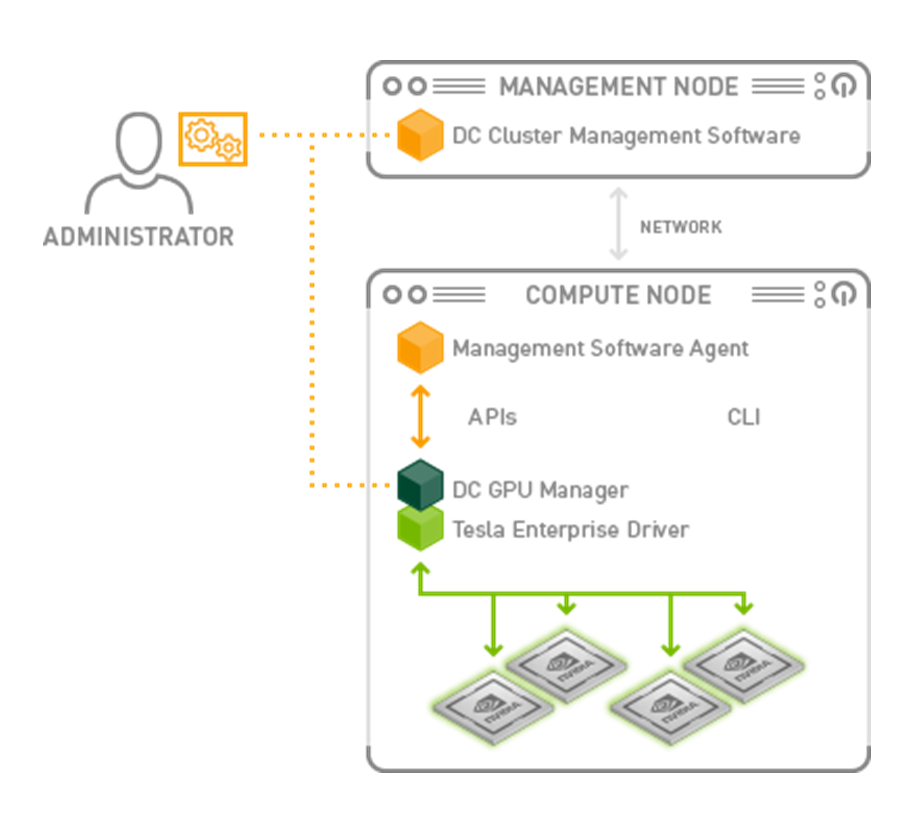
DCGM은 대규모 GPU 클러스터 운영에 특히 적합합니다. Kubernetes나 Slurm과 같은 클러스터 관리 환경에서 쉽게 배포할 수 있으며, Prometheus, Grafana와 같은 모니터링 툴과 통합이 쉬워 실시간 대시보드를 통해 모든 GPU의 상태를 한눈에 파악할 수 있는 기능을 제공합니다. 뿐만 아니라 모니터링 프로세스가 실행되는 동안 GPU에서 실행되는 어플리케이션의 동작과 성능에 영향을 주지 않고, 간섭을 최소화합니다.
DCGM 설치하기
우선 DCGM을 설치하고 실행해보겠습니다.
1.설치
Ubuntu 패키지 관리자 apt를 이용하여 datacenter-gpu-manager 패키지를 설치할 수 있습니다.
| sudo apt-get install -y datacenter-gpu-manager |
설치가 완료되면 DCGM과 필요한 구성 요소들이 시스템에 설치됩니다. 이후 GPU 상태와 성능을 확인하는 다양한 명령어를 사용할 수 있습니다.
2.실행
DCGM을 설치한 후, 다음 명령어를 입력하여 서비스가 자동으로 시작되도록 활성화합니다.
| sudo systemctl --now enable nvidia-dcgm |
DCGM 서비스가 활성화되면, dcgmi 명령어를 이용해 시스템에 설치된 GPU 디바이스를 확인할 수 있습니다.
dcgmi discovery -l 명령어를 실행하여 GPU 리스트를 출력합니다.
| sudo systemctl --now enable nvidia-dcgm |
3.출력 결과 확인
명령어를 실행하면 현재 시스템에서 감지된 GPU 목록이 출력됩니다. 아래는 예시입니다.
| 8 GPUs found. +--------+----------------------------------------------------------------------+ | GPU ID | Device Information | +--------+----------------------------------------------------------------------+ | 0 | Name: A100-SXM4-40GB | | | PCI Bus ID: 00000000:07:00.0 | | | Device UUID: GPU-1d82f4df-3cf9-150d-088b-52f18f8654e1 | +--------+----------------------------------------------------------------------+ | 1 | Name: A100-SXM4-40GB | | | PCI Bus ID: 00000000:0F:00.0 | | | Device UUID: GPU-94168100-c5d5-1c05-9005-26953dd598e7 | +--------+----------------------------------------------------------------------+ ...... |
출력 결과에는 시스템에 장착된 각 GPU의 ID, 모델명, PCI 버스 ID, 그리고 고유 UUID 정보가 포함됩니다. 이 정보를 통해 DCGM이 GPU를 정상적으로 인식했는지 확인할 수 있으며, 각 GPU에 접근하고 모니터링할 준비가 되었음을 의미합니다.
DCGM이 설치 및 정상 실행되면, GPU 모니터링 환경 설정이 완료된 것입니다. 이제 DCGM이 제공하는 다양한 지표와 기능을 통해 GPU 클러스터의 상태를 지속적으로 점검할 수 있습니다. 하지만 이 지표들을 관리 서버에서 효과적으로 호출하고 관리하기 위한 추가적인 유용한 도구가 있습니다.
DCGM-Exporter
DCGM-Exporter는 DCGM의 데이터를 손쉽게 외부 모니터링 툴에 연동할 수 있도록 도와주는 구성 요소입니다. DCGM이 수집한 GPU 상태 데이터를 Prometheus 형식으로 변환하여 제공하며, Prometheus와 Grafana와 같은 시각화 도구와 연동해 실시간 대시보드를 구축할 수 있습니다. DCGM-Exporter는 Go 언어로 작성되어 Go API를 기반으로 하는 도구입니다. 독립적인 컨테이너로 실행할 수도 있고, Kubernetes 클러스터의 GPU 노드에 deamonset으로 배포할 수도 있습니다. K8S에서 DCGM 통합에 대한 자세한 가이드는 아래 이미지의 출처 링크에서 확인할 수 있습니다.
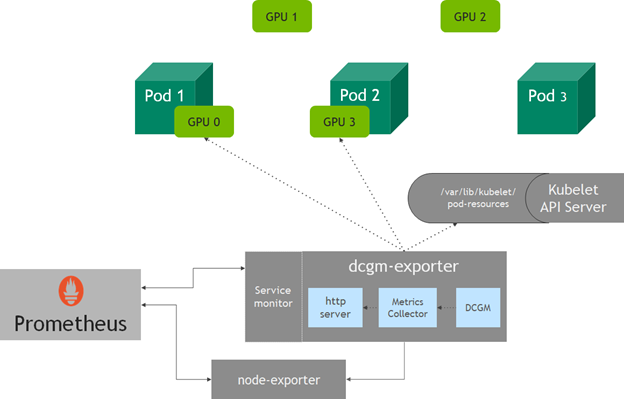
일반 서버에서는 단순히 아래와 같은 명령어로 DCGM-Exporter 컨테이너를 실행할 수 있습니다.
| # Ubuntu 20.04 docker run -d --gpus all --rm -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.2.3-3.1.6-ubuntu20.04 # Ubuntu 22.04 docker run -d --gpus all --rm -p 9400:9400 nvcr.io/nvidia/k8s/dcgm-exporter:3.3.8-3.6.0-ubuntu22.04 |
컨테이너 실행이 완료되면 9400번 포트로 API 서버가 실행됩니다. HTTP 엔드포인트에서 /metrics 를 통해 GPU 상태 지표를 확인할 수 있습니다.
| curl localhost:9400/metrics # HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz). # TYPE DCGM_FI_DEV_SM_CLOCK gauge DCGM_FI_DEV_SM_CLOCK{gpu="0",UUID="GPU-eth5w4aer5g4a6r5h4aeae68rh4a6e5r4g6a",device="nvidia0",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1410 DCGM_FI_DEV_SM_CLOCK{gpu="1",UUID="GPU-ah4ed65r4ga65wd4g6W5RHA654DFA5SD4G6S",device="nvidia1",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1410 DCGM_FI_DEV_SM_CLOCK{gpu="2",UUID="GPU-w65ge46ad514f3s2dg5we4gfaweg4as622gs",device="nvidia2",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1410 DCGM_FI_DEV_SM_CLOCK{gpu="3",UUID="GPU-xb4s6rdjn4EWArt46dsf54adfha5f4ga54rh",device="nvidia3",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1410 DCGM_FI_DEV_SM_CLOCK{gpu="4",UUID="GPU-t4ty65eu4r56t4h65rsd4hs6d5fhj4as6etr",device="nvidia4",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1410 DCGM_FI_DEV_SM_CLOCK{gpu="5",UUID="GPU-56erj4qaerf65WHJ4AE6TKS4s5g4a6r5jae6",device="nvidia5",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1410 DCGM_FI_DEV_SM_CLOCK{gpu="6",UUID="GPU-4kjtry654h65ae4t6wr54yawsreftgwr2h1e",device="nvidia6",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1410 DCGM_FI_DEV_SM_CLOCK{gpu="7",UUID="GPU-i4e6t54h6eas5f4ga6d5fj4ta6ret5y4as65",device="nvidia7",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1410 # HELP DCGM_FI_DEV_MEM_CLOCK Memory clock frequency (in MHz). # TYPE DCGM_FI_DEV_MEM_CLOCK gauge DCGM_FI_DEV_MEM_CLOCK{gpu="0",UUID="GPU-eth5w4aer5g4a6r5h4aeae68rh4a6e5r4g6a",device="nvidia0",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1512 DCGM_FI_DEV_MEM_CLOCK{gpu="1",UUID="GPU-ah4ed65r4ga65wd4g6W5RHA654DFA5SD4G6S",device="nvidia1",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1512 DCGM_FI_DEV_MEM_CLOCK{gpu="2",UUID="GPU-w65ge46ad514f3s2dg5we4gfaweg4as622gs",device="nvidia2",modelName="NVIDIA A100 80GB PCIe",Hostname="fa95f00c15f7",DCGM_FI_DRIVER_VERSION="525.147.05"} 1512 ...... |
DCGM Exporter에서 기본적으로 설정된 지표들 중에는 클럭, vgpu 라이선스 상태 등 모니터링에 큰 의미를 갖지 않는 항목들도 포함되어 있습니다. 효율적인 모니터링을 위해 필요한 지표들만 선택적으로 출력하도록 설정을 변경해 보겠습니다. 수집할 수 있는 지표의 목록은 DCGM API 가이드에서 확인할 수 있습니다.(Field Identifiers — NVIDIA DCGM Documentation latest documentation )
우선 실행한 컨테이너에 접속하면, /etc/dcgm-exporter/default-counters.csv 파일이 구성되어 있습니다. 해당 csv 파일을 복사하여 컨테이너 밖에서 수정합니다.
주로 사용하는 지표들은 기존 파일에 주석처리된 채 포함되어 있으니 주석을 제거해주고, 새로운 지표를 추가하고자 하면 형식에 맞추어 추가 작성해주면 됩니다. 각 행은 {지표}, {Prometheus metric 타입}, {설명} 형식으로 작성합니다. 만약 Prometheus를 사용하지 않는다면, gauge/counter 등 임의로 넣어주어도 됩니다.
| # Format # If line starts with a '#' it is considered a comment # DCGM FIELD, Prometheus metric type, help message # Clocks DCGM_FI_DEV_SM_CLOCK, gauge, SM clock frequency (in MHz). DCGM_FI_DEV_MEM_CLOCK, gauge, Memory clock frequency (in MHz). # Temperature DCGM_FI_DEV_MEMORY_TEMP, gauge, Memory temperature (in C). DCGM_FI_DEV_GPU_TEMP, gauge, GPU temperature (in C). # Power DCGM_FI_DEV_POWER_USAGE, gauge, Power draw (in W). DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION, counter, Total energy consumption since boot (in mJ). |
수정 후, 기존 이미지에서 해당 파일을 덮어쓰기 위한 Dockerfile을 만들어 Rebuild 합니다.
| # Dockerfile FROM nvcr.io/nvidia/k8s/dcgm-exporter:3.2.3-3.1.6-ubuntu20.04 COPY default-counters.csv /etc/dcgm-exporter/default-counters.csv |
| docker build -t nvcr.io/nvidia/k8s/dcgm-exporter:3.2.3-3.1.6-ubuntu20.04 . |
다시 docker run을 통해 컨테이너를 실행시킨 후 /metrics 엔드포인트로 요청을 날려, 설정한 지표들이 정상 출력되는 지 확인합니다. 이제 GPU 서버에서 각 디바이스에 대한 지표를 Master 관리 서버로 내보내기 위한 준비를 마쳤습니다.
kt cloud AI플랫폼팀에서 GPU Device를 모니터링 하는 방법
이전 목차에서 GPU 서버에서 DCGM-Exporter 컨테이너를 실행하고, 엔드포인트를 통해 지표를 출력하는 방법을 소개하였습니다. 이러한 방법으로 수 백대의 GPU 서버에서 DCGM-Exporter를 실행시키고 Master 관리 서버에서 각 GPU 서버로부터 Metric 수집 API를 호출하여 종합적으로 모니터링하면, 대규모 GPU 클러스터의 상태를 일괄적으로 관리할 수 있습니다.
Kubernetes와 같은 클러스터 관리 플랫폼이 있다면 DCGM을 쉽게 통합하는 방법도 존재하지만, 저희 kt cloud의 AI 서비스는 Kubernetes를 사용하지 않습니다. K8S 환경에서 GPU를 가상화하여 제공할 경우, 온전한 하드웨어 성능을 내지 못하기 때문이죠. AI 워크로드에 따라 일반적으로 5%에서 20% 정도까지 성능 저하가 발생할 수 있다고 알려져 있습니다. H100이나 A100과 같은 고성능 고비용 GPU를 제공할 때 하드웨어의 성능을 온전히 활용하지 못하는 점은 특히 치명적입니다. 뿐만 아니라 자원 할당과 회수, 그리고 GPU 자원의 효율적 활용을 위한 GPU 분할 설정에서도 Kubernetes는 오히려 손실을 초래할 수 있습니다. 필연적으로 MIG(Multi Instance GPU) 기능을 사용해야 하지만, 이 경우 일부 디바이스 자원을 포기해야 하는 상황이 발생합니다.
이러한 이유로, 저희는 Docker 기반의 컨테이너를 직접적으로 사용할 수 있도록 하는 솔루션을 통해 GPU 서비스를 제공하고 있습니다. 때문에 DCGM을 활용하여 각 GPU 서버들에서 데이터를 추출, 통합하여 관리하는 로직도 직접 설정하고 있습니다. GPU Utilization이나 Memory Usage 등 주요 지표들은 관리 솔루션에서 제공하고 있기 때문에, DCGM을 사용하는 가장 큰 목적은 오류/장애 탐지입니다. 아래와 같은 스크립트를 주기적으로 실행하여 오류가 발생하는 서버 및 GPU 디바이스를 식별하고 이를 출력할 수 있습니다.
| import requests # 모니터링할 서버 목록 ips = ["172.25.172.1", "172.25.172.2", "172.25.172.3", ...] # DCGM 지표 키워드 목록 metrics_keywords = ["DCGM_FI_DEV_XID_ERRORS", "DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS", "DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS", "DCGM_FI_DEV_ROW_REMAP_FAILURE"] def fetch_and_parse_metrics(ip): try: response = requests.get(f"http://{ip}:9400/metrics") response.raise_for_status() lines = response.text.splitlines() for line in lines: # 유효한 DCGM 지표 라인만 확인 if any(keyword in line for keyword in metrics_keywords): parts = line.split() # parts 마지막 요소가 숫자인지 확인 try: metric_value = int(parts[-1]) if metric_value != 0: # 지표 정보 파싱 metric_info = parts[0].split("{")[0][12:] gpu_info = parts[0].split("gpu=\"")[1].split("\"")[0] print(f"{ip}서버의 {gpu_info}번 GPU에서 {metric_info} {metric_value}번 발생했습니다.") except ValueError: # 마지막 요소가 숫자가 아니면 건너뜀 continue except requests.RequestException as e: print(f"{ip}에서 데이터를 가져오는 중 오류 발생: {e}") # 각 IP에 대해 메트릭 요청 및 파싱 for ip in ips: fetch_and_parse_metrics(ip) |
마무리
이번 글에서는 NVIDIA DCGM을 활용한 GPU 장애 모니터링 시스템의 구성 방법과 효과를 살펴보았습니다. DCGM을 통해 GPU의 상태를 실시간으로 모니터링하고, 오류 및 장애를 신속히 탐지함으로써 대규모 GPU 클러스터를 안정적으로 운영할 수 있었습니다. 특히 GPU의 온도, 전력 소모, 메모리 사용률 등 핵심 지표를 통합하여 관리하고, 오류를 탐지할 경우 알림을 전송하는 시스템을 구축하여 예상치 못한 장애로 인한 다운타임을 최소화할 수 있었습니다.
앞으로도 AI플랫폼팀은 DCGM의 기능을 포함해 더욱 정밀한 예측과 자동화된 문제 해결 시스템을 구축해 나갈 계획입니다. 이를 통해 AI 워크로드의 안정적이고 효율적인 수행을 보장하고, 고객에게 최상의 성능을 제공하는 AI 플랫폼을 지속적으로 유지해 나가겠습니다.
기타/출처
'Tech Story > AI Cloud' 카테고리의 다른 글
| [kt cloud] GPU 파워의 AI Train 고속열차 타고 AI 학습의 종착역으로 (3) | 2025.02.10 |
|---|---|
| [튜토리얼] kt cloud AI로 배우는 RAG 개념 구현하기: FAISS로 시작하는 첫걸음 (0) | 2025.02.06 |
| NPU로 sLM 서빙하기: 새로운 가능성 탐구 (0) | 2024.10.31 |
| AMD MI250 GPU로 vLLM 최적화 하기 (feat. AI SERV) (1) | 2024.10.14 |
| [K2P&HAC] 초거대 AI 활용을 위한 Hyperscale AI Computing과 Container 서비스 (0) | 2023.10.23 |