

[kt cloud AI플랫폼팀 최지우 님]

AMD MI250 GPU로 vLLM 최적화하기
최근 대규모 언어 모델(LLM)의 발전과 함께 인공지능 연구 및 상용화 과정에서 GPU의 수요가 급격히 증가하고 있습니다. 특히, NVIDIA는 이 분야에서 시장을 주도하며 AI 연산에 필수적인 GPU 기술을 제공하고 있지만, 수요에 비해 공급이 부족하고 가격이 높아지는 문제가 발생하고 있습니다. 이러한 상황에서 많은 기업과 연구 기관들은 더 경제적이면서도 성능이 뛰어난 대안을 모색하고 있습니다.
그 중 하나가 vLLM 프로젝트입니다. vLLM은 LLM 추론 및 제공을 위한 빠르고 사용하기 쉬운 라이브러리입니다. PagedAttention을 이용하여 Key-Value(KV) Cache가 저장되는 메모리를 block 단위로 나누어, 낭비되던 메모리를 줄이고 Throughput을 개선시켰으며, NVIDIA GPU 뿐만 아니라 AMD ROCm, TPU XLA, 그리고 AWS Neuron도 지원한다는 점이 특징입니다.
이번에는 AMD MI250 GPU를 이용하여 vLLM을 통해 모델을 추론하고 서빙하는 방법을 소개해보겠습니다.
AMD MI250 GPU 개요
AMD MI250은 CDNA2 아키텍처를 기반으로 한 GPU로, 고성능 연산을 위해 설계되었습니다. 128GB HBM2e 메모리와 3.2TB/s의 메모리 대역폭을 제공하여 대규모 모델 학습에 최적화되어 있습니다. FP32에서 연산 처리량이 45.3 TFLOPs / (Peak) 90.5 TFLOPs 으로, 이론 상 A100보다 2배 이상의 처리량을 보인다고 합니다.
또한 NVIDIA의 CUDA에 대응하는 ROCm(Radeon Open Compute platform) 소프트웨어 스택을 통해 AI 및 HPC 워크로드를 지원하여, PyTorch와 같은 주요 딥러닝 프레임워크와의 호환성을 제공합니다.
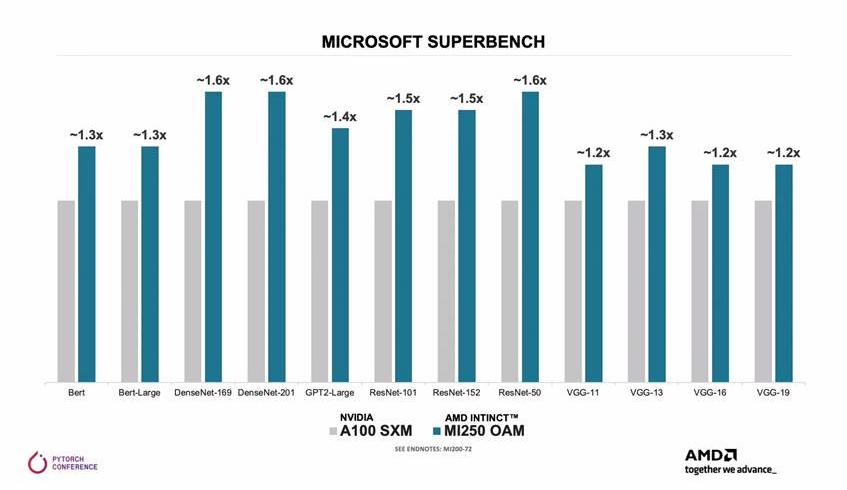
AMD는 2023년 PyTorch 2.0 공개 컨퍼런스에서 벤치마크를 통해 MI250이 동시대 제공된 NVIDIA의 A100 보다 전체적인 성능이 최대 1.6배까지 높게 관측된다고 주장하였습니다.
그렇다면 왜 많은 AI 개발자들은 AMD GPU를 AI 워크로드에 사용하지 않을까요?
가장 큰 이유 중 하나는 바로 소프트웨어 생태계의 부족입니다. AI 작업에서 하드웨어만큼이나 중요한 것이 소프트웨어 호환성과 최적화인데, NVIDIA는 CUDA와 같은 강력한 소프트웨어 툴을 제공하며, 이를 통해 연구자들과 개발자들이 손쉽게 AI 모델을 구축하고 최적화할 수 있습니다. 반면, AMD는 ROCm(Radeon Open Compute)이라는 오픈 소스 소프트웨어 플랫폼을 제공하고 있지만, 여전히 호환성 문제나 안정성 부족으로 인해 많은 개발자들이 어려움을 겪고 있습니다. ROCm의 경우 특정 하드웨어에서만 제대로 작동하거나, 다양한 프레임워크와의 통합이 미흡해 사용자 경험이 좋지 않다는 비판을 받고 있습니다. 게다가 이를 지원하는 커뮤니티나 자료도 상대적으로 부족해, 새로운 기술을 도입하기 어려운 기업이나 연구소에서는 AMD를 선택하는 것을 꺼려하게 되는 것이 현실입니다.
사용자들은 당연히 NVIDIA CUDA 기반으로 작성한 코드를 그대로 AMD GPU에서도 실행할 수 있기를 바랍니다. 다행히 vLLM에서는 AMD GPU에서도 동일한 코드로 작업할 수 있는 환경을 제공합니다. CUDA에 종속되지 않고도 LLM을 효과적으로 운영할 수 있는 이점 덕분에, 개발자들은 자신이 작성한 기존의 모델을 큰 수정 없이 AMD GPU에서 실행할 수 있습니다. 이를 통해 NVIDIA의 독점적 생태계에서 벗어나 좀 더 다양한 하드웨어 선택지를 가질 수 있는 가능성이 열립니다.
vLLM에서 MI250 vs. A100
우선 실제로 AMD MI250과 NVIDIA A100 간의 성능을 비교해 보겠습니다. vLLM 프로젝트의 벤치마크( vllm/benchmarks at main · vllm-project/vllm · GitHub ) 를 기반으로, 동일한 조건에서 두 GPU의 처리 성능을 테스트하였습니다.
kt cloud AI SERV 환경에서 벤치마크는 동일한 모델과 워크로드를 대상으로 했으며, 각 GPU의 Latency와 Throughput 등을 측정하였습니다.
- kt cloud AI SERV 컨테이너 환경
- 8 CPU 128GB Memory (공통)
- NVIDIA A100 SXM 80GB - vLLM 0.6.2.post1 (CUDA 12.1)
- AMD Instinct MI250 128GB - vLLM 0.6.1.post2 (ROCm 6.2)
- Model: meta-llama/Meta-Llama-3.1-8B (공통)
- Dataset: ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json (Throughput 한정, 공통)
NVIDIA A100 SXM (80GB) 1GPU - Latency (Tensor Parallel = 1)

A100의 평균 Latency는 1.61 초 입니다.
AMD MI250 (128GB) 1GPU - Latency (Tensor Parallel = 2)
[MI250은 하나의 GPU보드에 2개의 칩(각 64GB)이 장착되어 있으므로, 인식 되는 Device는 2로 표기됩니다.]

평균 Latency는 2.11초 입니다.
MI250은 A100 대비 76%의 성능(Latency)을 보입니다.
NVIDIA A100 SXM (80GB) 1GPU - Throughput (Tensor Parallel = 1)

A100의 Throughput은 16.73 requests/s, 6919.96 tokens/s 입니다.
AMD MI250 (128GB) 1GPU - Throughput (Tensor Parallel = 2)

평균 Throughput는 1.58 requests/s, 653.13 tokens/s 입니다.
Throughput에서는 거의 1/10 수준의 성능을 보이고 있습니다.
AMD가 주장하는 성능에는 미치지 못하는 듯 합니다. 이제 이 성능을 어떻게든 끌어 올려보도록 하겠습니다.
MI250 성능 최적화하기
AMD ROCm에서는 AI 워크로드에서 연산을 효율적으로 나누어 처리하고, 알고리즘 복잡도를 감소시키는 Composable Kernel(CK) 라이브러리를 제공합니다.
vLLM에서는 기본적으로 Triton이 자동 튜닝을 수행한 후 벤치마킹 수치를 수집하도록 설정되어 있습니다. CK Flash Attention을 사용하려면 환경 변수를 다음과 같이 설정합니다.
1) export VLLM_USE_TRITON_FLASH_ATTN=0
다시 throughput을 측정해보겠습니다.
1) VLLM_USE_TRITON_FLASH_ATTN=0 python benchmark_throughput.py \
2) --model meta-llama/Meta-Llama --dtype float16 --dataset ShareGPT_V3_unfiltered_cleaned_split.json \
3) --tensor-parallel-size 2

Flash Attention 방법을 변경한 것 만으로 1.54 requests/s → 12.18 requests/s, 637.67 tokens/s → 5035.03 tokens/s로 크게 개선되었습니다.(약 7.9배 개선)
하지만 아직 부족합니다.
vLLM의 성능을 향상시키기 위한 또 다른 팁은 chunked prefill을 활성화하는 것입니다. 이 기능을 사용하면 대량의 prefill을 작은 청크로 나누어, 디코드 요청과 함께 배치할 수 있습니다. --enable-chunked-prefill 옵션을 활성화하여 다시 throughput을 측정해보겠습니다.

12.18 requests/s → 12.81 requests/s , 5035.03 tokens/s → 5296.49 tokens/s
이번에도 약간의 성능이 향상되었습니다.(이전 단계 대비 약 5% 개선)
vLLM의 문서에 따르면, 성능을 조절하려면 max_num_batched_tokens 값을 변경하는 것이 중요하다고 합니다. 기본적으로 이 값은 512로 설정되어 있으며, 이는 토큰 간 지연 시간(ITL)을 최적화하도록 설계되었습니다. 이 값을 낮추면, 디코드 과정에서 prefill이 방해하는 횟수를 줄여 ITL을 개선시킬 수 있습니다. 반대로, 값을 높이면 배치당 처리할 수 있는 prefill의 양이 많아져 첫 번째 토큰까지의 시간(TTFT)을 단축시킬 수 있습니다.
다음에는 몇 가지 환경변수를 추가해보겠습니다.
NVIDIA CUDA에서 채널 수를 늘려 사용하는 CUDA 블록 수를 늘렸던 것 처럼, ROCm에서도 RCCL 채널 수를 늘려보겠습니다. CUDA에서 사용하던 환경변수와 동일합니다.
1) export NCCL_MIN_NCHANNELS=112
HIP은 HIP 커널의 인수를 직접 디바이스 메모리에 배치하여 커널 인수 접근 시 지연 시간을 줄일 수 있습니다. 일부 커널의 경우 성능이 2~3 µs 향상될 수 있다고 합니다.
1) export HIP_FORCE_DEV_KERNARG=1
OpenMP 라이브러리가 병렬처리를 할 때 사용하는 스레드 수도, Core 수에 맞게 늘려줍니다.
1) export OMP_NUM_THREADS=8
3가지 환경변수를 설정 후 다시 Throughput을 체크해보겠습니다.

12.81 requests/s → 14.48 requests/s , 5296.49 tokens/s → 5987.83 tokens/s
거의 다 따라왔습니다. 이제 A100이 보이는 성능까지 한 걸음 남았습니다.
마지막으로, num_scheduler_steps를 20으로 설정해보겠습니다.(이 경우, chunked-prefill을 비활성화하여야 합니다.) num_scheduler_steps는 함수에서 모델을 통해 데이터를 처리할 때, 스케줄러가 한 번 호출될 때 수행할 최대 포워드 단계 수를 지정합니다. 스케줄러는 모델의 진행 상태를 조정하고 최적화를 돕는 역할을 합니다. 이 값이 클수록 각 호출에서 처리하는 포워드 단계의 수가 많아지지만, 너무 높게 설정하면 메모리 사용량과 연산 부담이 증가할 수 있습니다. 기본값은 1로, 각 호출에서 한 단계씩 처리하게 됩니다. 그리고, 기본적으로 MI250은 A100보다 메모리 용량이 크기 때문에, 그래프 저장에 필요한 GPU Memory 비율을 좀 더 낮추어도 됩니다.
1) --num-scheduler-steps 20 # default = 1
2) --gpu-memory-utilization 0.98 # default = 0.9

최종 Throughput은 15.48 requests/s, 6402.76 tokens/s 으로 측정되었습니다. A100의 결과값과 유사한 수준으로, 이 정도면 정말 많이 최적화된 것 같습니다.
(A100 16.73 requests/s, 6919.96 tokens/s)
최종 실행 명령은 아래와 같습니다.
1) OMP_NUM_THREADS=8 \
2) NCCL_MIN_NCHANNELS=112 \
3) HIP_FORCE_DEV_KERNARG=1 \
4) VLLM_USE_TRITON_FLASH_ATTN=0 \
5) python benchmark_throughput.py \
6) --model meta-llama/Meta-Llama-3.1-8B \
7) --dtype float16 --dataset ShareGPT_V3_unfiltered_cleaned_split.json \
8) --tensor-parallel-size 2 \
9) --num-scheduer-steps 20 \
10) --gpu-memory-utilization 0.98
기존 vLLM에서 활용했던 것 처럼, vllm serve 명령어로 모델을 서빙할 수도 있습니다.
1) vllm serve meta-llama/Meta-Llama-3.1-8B --tensor-parallel-size 2
직접 실행한 vLLM 모델 서빙 서버로, benchmark_serving.py를 통해 특정한 성능은 아래래와 같습니다.

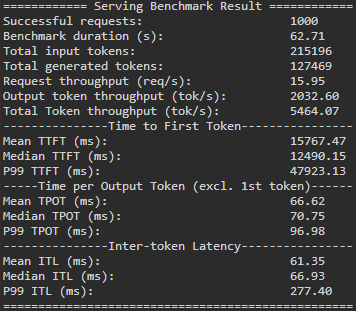
NVIDIA A100 GPU 성능만큼은 미치지 못하지만, 사용자가 크게 체감할 정도는 아닙니다. 초기 측정한 수치보다도 크게 개선되었습니다.
하지만 아직도 성능이 최적화될 가능성은 열려 있습니다. 추가적인 성능 개선을 위한 옵션들은 ROCm 공식 홈페이지에서 찾아보실 수 있습니다.
( Performance guidelines — HIP 6.2.41134 Documentation (amd.com))
마무리
AMD GPU를 활용한 AI 워크로드는 하드웨어 자체는 뛰어나지만, 소프트웨어 지원 측면에서는 여전히 많은 개선이 필요한 상황입니다. 마치 AMD는 강력한 GPU를 사용자에게 제공하면서도 "소프트웨어는 오픈소스를 활용해 알아서 최적화하라"는 느낌을 주는 경우가 많죠. NVIDIA의 CUDA와 같은 통합된 생태계에 비해, ROCm을 포함한 소프트웨어 스택이 덜 성숙해 보일 수 있는 건 사실입니다.
하지만 그럼에도 불구하고, AMD 하드웨어를 사용하는 이점은 분명합니다. 하드웨어 성능을 최대한 끌어올리기 위해서는, 사용자가 직접 소프트웨어를 최적화하고 ROCm과 같은 오픈소스 도구를 활용해 성능을 끌어내야 합니다. 물론 이는 더 많은 노력이 필요하지만, 제대로 세팅하고 최적화한다면 비용 효율적인 AI 워크로드 구현이 가능합니다.
AMD MI250 GPU는 2024년 10월 말, kt cloud AI SERV 서비스에서 만나보실 수 있습니다.
참고/출처
'Tech Story > AI Cloud' 카테고리의 다른 글
| GPU 1,000장 모니터링 하기: NVIDIA DCGM 활용 전략 (14) | 2024.11.07 |
|---|---|
| NPU로 sLM 서빙하기: 새로운 가능성 탐구 (0) | 2024.10.31 |
| [K2P&HAC] 초거대 AI 활용을 위한 Hyperscale AI Computing과 Container 서비스 (0) | 2023.10.23 |
| kt cloud 봇과 함께 클라우드와 가까워지세요! (0) | 2021.04.13 |
| GPU란 무엇일까? 1부 (1) | 2021.01.18 |