

[kt cloud Container개발팀 박지선 님]

#1.Prometheus와 함께하는 Kubernetes 모니터링
Kubernetes는 containerized 애플리케이션을 자동으로 배포, 스케일링, 운영하는 컨테이너 오케스트레이션 플랫폼입니다.
Kubernetes 자체가 오픈소스로 개발되었기 때문에 전 세계의 개발자와 기업들이 함께 발전시키고 있으며, 이를 둘러싼 많은 오픈소스 프로젝트들이 Kubernetes의 기능을 확장하거나 보완하고 있습니다. 다양한 오픈소스와 활용되었을때 Kubernetes 는 가장 큰 시너지를 발휘합니다.
[Kubernetes+Opensource Project] 이 광범위한 환경을 일명 Kubernetes 오픈소스 생태계 (Kubernetes Open source Ecosystem)이라고도 부르는데요, 본 포스팅은 이 생태계의 일부 조각을 하나씩 탐구해보는 시리즈 입니다
첫번째는 바로 Metric 모니터링 영역 입니다.
대표 오픈소스로 Promethues를 소개합니다.
이 글에서는 Prometheus에 대하여 살펴보고, Kubernetes 환경에서 Prometheus를 설정 후 Grafana 와 연동하여 대시보드를 생성하는 방법까지 다뤄보겠습니다.
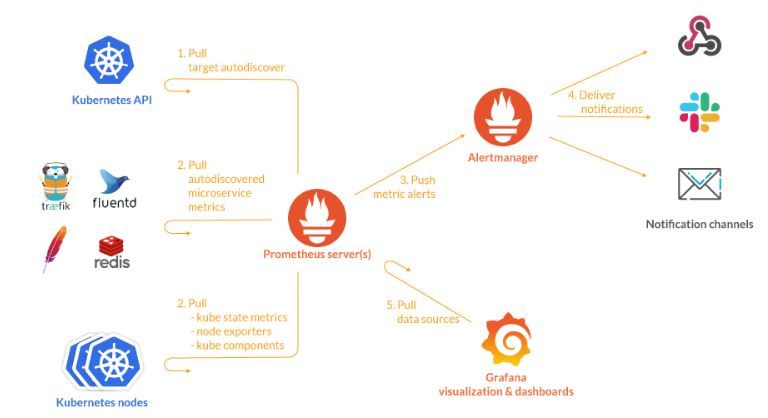
1.Prometheus란 무엇인가?
Prometheus는 2012년 SoundCloud에서 시작된 오픈소스 프로젝트 인데요, 시계열 데이터베이스를 기반으로 한 모니터링 및 경고 시스템으로, 메트릭 수집과 저장, 쿼리를 지원합니다. 특히 Kubernetes의 동적인 환경에서, 각 Pod, Node, 클러스터의 Metric데이터를 실시간으로 분석해 성능 상태를 모니터링하는데 유용합니다. 따라서 Kubernetes 사용 시 필수로 설치하는 오픈소스 중 한가지 입니다.
특장점
- 각 데이터는 시간과 함께 수집되어 시계열 데이터(TSDB)로 저장됩니다.
- Prometheus의 쿼리 언어인 PromQL은 다양하고 디테일한 분석 및 경고 조건을 설정할 수 있습니다.
- `scraping`이라고 불리는 방식을 통해 지표 데이터를 가져옵니다.
Prometheus의 확장
Kubernetes 환경의 Prometheus는 부가적인 tool을 설치하면 더 높은 효율성과 확장성을 제공합니다.
- 시각화 툴인 Grafana: Prometheus가 수집한 Metric 데이터를 훨씬 더 쉽게 분석하고 시각적으로 표현할 수 있습니다.
- 확장성을 제공하는 Thanos: 다수의 Multi 클러스터 모니터링과 장기 데이터 저장에 용이한 tool 입니다.
- 경고 시스템 AlertManager: 특정 이벤트 발생 시, 알람을 발송하는 기능의 tool 입니다. email/slack 등 다양한 도구로 report를 수신 할 수 있습니다
이 외에도 다양한 오픈소스와 연계가 가능합니다
2.Prometheus 설치하기
가장 쉬운 방법은 Helm 차트를 사용하는 것입니다. Helm을 사용하면 쉽게 Prometheus와 관련된 모든 구성 요소를 배포할 수 있습니다.
[참고] 하기 예제는 kt cloud의 Kubernetes 상품인 K2P Standard 1.27로 클러스터 구축 후 수행하였습니다
1. Helm 리포지토리 추가
먼저 kubectl이 가능한 클러스터 내 노드로 접속한 뒤, helm 툴을 설치합니다.
helm repository에 Prometheus 차트를 추가합니다.
| # helm repository에 prometheus chart 추가 $ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts # repository update $ helm repo update # 확인 $ helm repo list NAME URL prometheus-community https://prometheus-community.github.io/helm-charts |
2. 클러스터에 설치
다음 명령어를 사용하여 Prometheus를 Kubernetes 클러스터에 설치합니다.
| # 전용 namespace 생성 $ kubectl create ns monitoring # 설치 $ helm install prometheus prometheus-community/prometheus --namespace monitoring NAME: prometheus NAMESPACE: monitoring (이하 생략) # 확인 $ kubectl -n monitoring get all |
이렇게 하면 Prometheus 서비스를 위한 `Service`, `Pod`, `Deployment`와 같은 Kubernetes 리소스가 자동으로 배포됩니다.
alertmanager와 promethues-server 는 pvc를 자동 생성하므로, pv가 별도 생성되어야 pod가 정상상태가 됩니다
본 예제에서는 pv를 미리 수동 생성해주었습니다.
Prometheus Helm 차트에는 다양한 구성요소가 포함되어 있습니다.
- Alertmanager: Prometheus 경고를 관리하고 알림을 발송하는 역할을 수행.
- kube-state-metrics: Kubernetes 리소스 상태에 대한 메트릭을 수집해 Prometheus에 제공.
- node-exporter: 각 노드의 CPU, 메모리 등 시스템 자원 사용량을 수집해 Prometheus에 제공.
- prometheus-pushgateway: 수명이 짧은 작업이 메트릭을 Prometheus에 푸시할 수 있게 해줌.
- prometheus-server: Prometheus 메트릭을 수집하고 저장하며, 쿼리와 경고 기능을 제공.
3.Prometheus 활용하기
1. 수집 데이터 설정
설치가 정상적으로 되면 Prometheus는 Kubernetes의 서비스 메트릭을 자동으로 수집하게 됩니다.
기본적으로 Prometheus는 `scrape` 설정을 통해 어떤 서비스를 모니터링할지 결정합니다. 클러스터에 설치 후 scrap 설정을 변경하는 방법은 prometheus-server 라는 이름의 configMap(cm) 을 수정하면 됩니다
수정이 필요하면 .data.prometheus\.yml.scrap_configs 필드 하위의 각 job에 대한 부분을 수정하면 됩니다.
| $ kubectl -n monitoring get cm prometheus-server -oyaml --- apiVersion: v1 data: prometheus.yml: | scrape_configs: # scrap 설정 정보 - job_name: kubernetes-pods kubernetes_sd_configs: - role: pod (중략) - job_name: kubernetes-nodes kubernetes_sd_configs: - role: node (이하 생략) |
이 configMap을 통해 Prometheus는 Kubernetes 클러스터에서 Metric 데이터를 수집합니다. 추가로, 수집 데이터 커스터마이징을 하고 싶다면 configMap object를 활용해서 할 수 있습니다.
2. Grafana 설치
시각화 도구인 Grafana도 설치해서 대시보드를 만들어 보고자 합니다. 역시 Helm을 통해 간편하게 설치할 수 있습니다.
| # helm repository에 grafana chart 추가 & update $ helm repo add grafana https://grafana.github.io/helm-charts $ helm repo update # 설치 $ helm install grafana grafana/grafana --namespace monitoring # 확인 $ kubectl -n monitoring get all | grep grafana |
3. Grafana 데이터 소스 설정
Grafana를 별도로 설치했으므로, 데이터 소스(data source)를 Prometheus로 지정해주는 작업을 해야합니다.
grafana-datasources 이름의 configMap을 만들어, prometheus-server Service(svc)를 사용하도록 설정합니다.
| # configMap yaml 파일 생성 $ vi grafana-datasource_cm.yaml --- apiVersion: v1 kind: ConfigMap metadata: name: grafana-datasources labels: grafana_datasource: "1" data: prometheus-datasource.yaml: | apiVersion: 1 datasources: - name: Prometheus type: prometheus access: proxy url: http://prometheus-server.monitoring.svc:80 ##prometheus-server svc이 기본 포트가 80이라 그대로 사용 isDefault: true editable: true # 생성하기 $ kubectl -n monitoring create -f grafana-datasource_cm.yaml # 확인 $ kubectl -n monitoring get cm |
grafana Deployment(deploy)에도 생성한 cm을 볼륨으로 설정해줍니다. 설정 후 grafana pod는 재기동 됩니다.
| $ kubectl -n monitoring edit deploy grafana --- apiVersion: apps/v1 kind: Deployment metadata: name: grafana spec: spec: containers: - name: grafana image: grafana/grafana:latest volumeMounts: # 하기 내용 추가 - name: grafana-datasources mountPath: /etc/grafana/provisioning/datasources readOnly: true volumes: # 하기 내용 추가 - name: grafana-datasources configMap: name: grafana-datasources # 확인 $ kubectl -n monitoring get po | grep grafana |
4. Grafana 대시보드 생성
웹 브라우저로 Grafana 에 접속해서 Kubernetes 클러스터의 각 pod 의 실시간 CPU, 메모리 사용량 대시보드를 만들어 보겠습니다.
네트워크 설정
grafana svc를 NodePort 타입으로 변경해서, IP:port 주소로 브라우저에 접속합니다.
| # NodePort 타입으로 변경 $ kubectl -n monitoring edit svc grafana (중략) spec: type: NodePort # 기본 ClusterIP 타입 -> NodePort로 수정 # 확인 $ kubectl -n monitoring get svc grafana NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE grafana NodePort 10.xx.xx.xx <none> 80:32496/TCP 18h # 80포트에 32496 포트가 자동 맵핑됨 |
Grafana 도메인 접속을 위해서는 ingress object를 생성하면 됩니다. 추가로 ingress 도메인 라우팅 처리를 위한 ingress controller 설치도 필요합니다.
외부에서 접속하기 위해 Public NAT 와 포트포워딩 까지 별도로 해주었습니다
브라우저에서 정상 접속되는것을 확인할 수 있습니다

접속 계정은 grafana 이름의 secret 에서 확인 가능합니다. (admin-user / admin-password)
대시보드 생성
- Dashboards 메뉴 > +New Dashboard 선택 > +Add visualization 선택
새로 대시보드를 생성해서, 모든 pod의 실시간 CPU 사용량 및 메모리 사용량 패널을 각각 추가합니다.
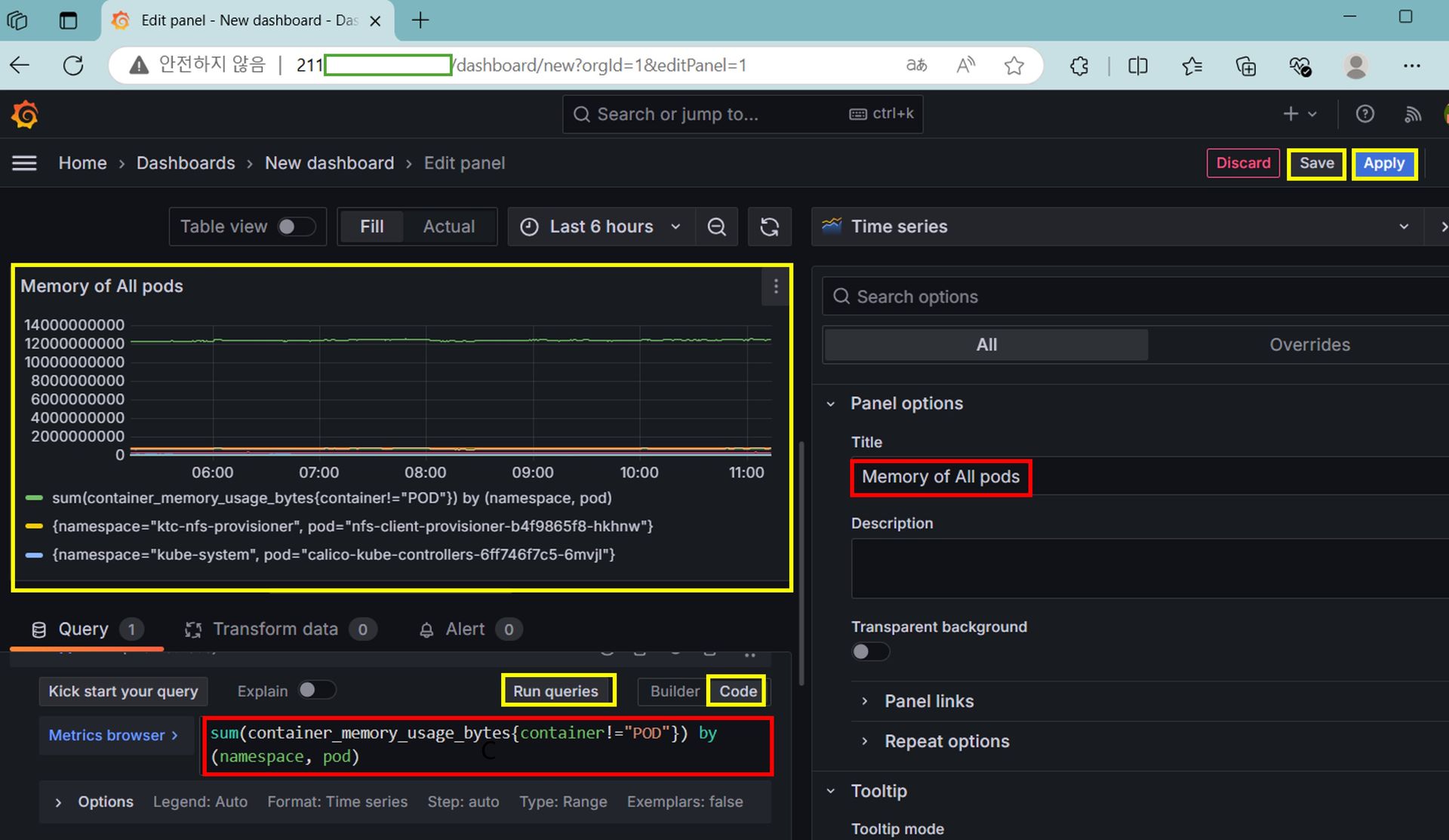
사용한 PromQL 예시입니다.
- CPU 사용량: sum(rate(container_cpu_usage_seconds_total{container!="POD"}[5m])) by (namespace, pod)
- 메모리 사용량: sum(container_memory_usage_bytes{container!="POD"}) by (namespace, pod)
완성한 대시보드 화면 입니다.

이와 같이 여러 툴을 연동해서 더 다양하고 편리한 실시간 모니터링을 할 수 있다는 것이 Prometheus 오픈소스의 큰 장점입니다.
마무리
Kubernetes 환경에서 Prometheus는 필수적인 모니터링 도구입니다. 클러스터와 pod의 성능을 실시간으로 추적하고, 이상 상태를 빠르게 감지하여 대응할 수 있게 해줍니다. 강력한 확장성과 다양한 통합 기능을 제공하므로, Kubernetes에서 운영되는 복잡한 마이크로서비스 환경을 관리하는 데 이상적인 도구입니다.
Grafana와의 통합을 통해 시각화를 강화하고, Alertmanager를 통해 실시간 경고 시스템을 구축하면 더욱 효율적인 클러스터 관리가 가능해집니다.
참고/출처
'Tech Story > DevOps & Container' 카테고리의 다른 글
| Spring Rest Docs로 REST API 문서 자동화 (3) | 2024.10.24 |
|---|---|
| 알아보기 1. Container Basic (1) | 2024.10.24 |
| [개발자 인터뷰] “kt cloud 멀티클라우드 구축 기술 제공으로, K-PaaS 생태계 주도권 선점 할 것” (0) | 2023.08.17 |
| 국내 최초 서버리스 컨테이너 서비스 KCI, K2P (2편) (1) | 2023.06.09 |
| 국내 최초 서버리스 컨테이너 서비스 kt cloud container (1편) (0) | 2023.05.10 |